Complete Guide to Semantic Segmentation
Semantic segmentation is an indispensable task in computer vision, providing a detailed understanding of the content within an image. It involves classifying each pixel in an image into a specific category, enabling machines to comprehend the semantic meaning of different regions within the visual scene. This technique has widespread applications across various fields, including autonomous driving, medical imaging, satellite imagery analysis, and more. In this article, we will take a closer look at the semantic segmentationdata annotation method to understand how it can be used to create AI products.
What is Semantic Segmentation?

At its core, semantic segmentation aims to assign a class label to each pixel in an image. Unlike classification tasks, where the goal is to classify an entire image into a single category, semantic segmentation provides a pixel-level understanding of the scene. The process typically involves utilizing deep learning architectures, especiallyconvolutional neural networks (CNNs), due to their ability to effectively capture spatial information in images. These networks are trained on large datasets with annotated pixel-level labels, learning to differentiate between different objects, backgrounds, and other semantic elements present in images. Semantic image segmentation can be used to train CNNs. Let’s dive deeper to understand segmentation, neural networks can be trained with semantic segmentation.
Teaching With CNN Segmentation: The Direct Method

It would make sense to attempt to adapt methods that are effective for image classification to the current task since, in general, our problem-at-hand classification task is similar to basic picture classification. The first foolish suggestion that springs to me is to employ a sliding window strategy. We can picture a sliding window of any size; in fact, any size will do, and we can attempt to categorize the central pixel of each pane.
This kind of strategy might be effective. It does, however, have a number of obvious drawbacks:
- Since it doesn’t reuse features that are shared between patches, it is incredibly wasteful.
- It makes inefficient use of spatial information, and depending on the image’s domain, varying sliding window sizes may produce varying accuracy performances. Larger windows will not be able to catch minute details, while smaller ones will lose the overall picture.
Cutting-Edge CNN-Driven Models Created With Semantic Segmentation
Semantic segmentation was used to create some of the best segmentation models. The computer vision community quickly discovered uses for deep convolutional neural networks on increasingly complex tasks, like object detection, semantic segmentation, keypoint detection, panoptic segmentation, etc., following their enormous success in the “ImageNet” project.
A minor alteration to thestate-of-the-art (SOTA) classification modelsserved as the foundation for the development of semantic segmentation networks. At the end of these networks, 1×1 convolutional layers were used in place of the customary fully connected layers, and as a final layer, a transposed convolution—interpolation followed by a convolution—was used to project back to the original input size. The first effective semantic segmentation networks were these basic fully convolutional networks (FCNs). The development of encoder-decoder designs that also included residual connections, which produced more precise and fine-grained segmentation maps, was the next significant advancement made by U-Net. Numerous minor modifications were made in response to these significant architectural ideas, producing a large variety of buildings, each with advantages of its own positives and negatives.
Top of the Line Vision Transformer Models
In addition to the best image segmentation models mentioned in the previous section, there are also some high-quality vision transformer models created with image semantic segmentation. A Transformer-like design is used over picture patches in the Vision Transformer, or ViT, image categorization model. After dividing a picture into fixed-size patches and linearly embedding each one, along with adding position embeddings, the series of vectors is put into a typical Transformer encoder. The conventional method of performing classification involves incorporating an additional learnable “classification token” into the sequence.
How Does the Segmenter Compare to Other Models
While CNNs are well-suited for handling large-scale datasets and have a track record in a variety of computer vision tasks, Vision Transformers are more advantageous in situations where contextual comprehension and global dependencies are critical. Nevertheless, in order to perform on par with CNNs,Vision Transformersusually need more training data. Additionally, because CNNs can be parallelized, they are computationally efficient and better suited for real-time and resource-constrained applications.
CNNs have long been the preferred option for image-processing jobs in the past. Through convolutional layers, they are particularly good at collecting local spatial patterns, which makes hierarchical feature extraction possible. CNNs have demonstrated amazing effectiveness in tasks like object detection, segmentation, and picture classification because they are skilled at learning from vast amounts of image data.
Applications of Semantic Segmentation

The versatility of semantic segmentation enables its application across various domains:
- Autonomous Vehicles – Semantic segmentation plays a crucial role in enabling vehicles to understand their surroundings and identifying pedestrians, vehicles, road markings, and other objects for safe navigation.
- Medical Imaging – In medical imaging, semantic segmentation aids in tasks such as tumor detection, organ segmentation, and disease diagnosis, facilitating more accurate and efficient healthcare practices.
- Satellite Imagery Analysis – Semantic segmentation helps analyze satellite images for urban planning, environmental monitoring, disaster response, and agricultural management.
- Augmented Reality – Semantic segmentation contributes to augmented reality applications by accurately segmenting objects in real time, enabling seamless integration of virtual elements into the physical environment.
Labeling Images for Semantic Segmentation
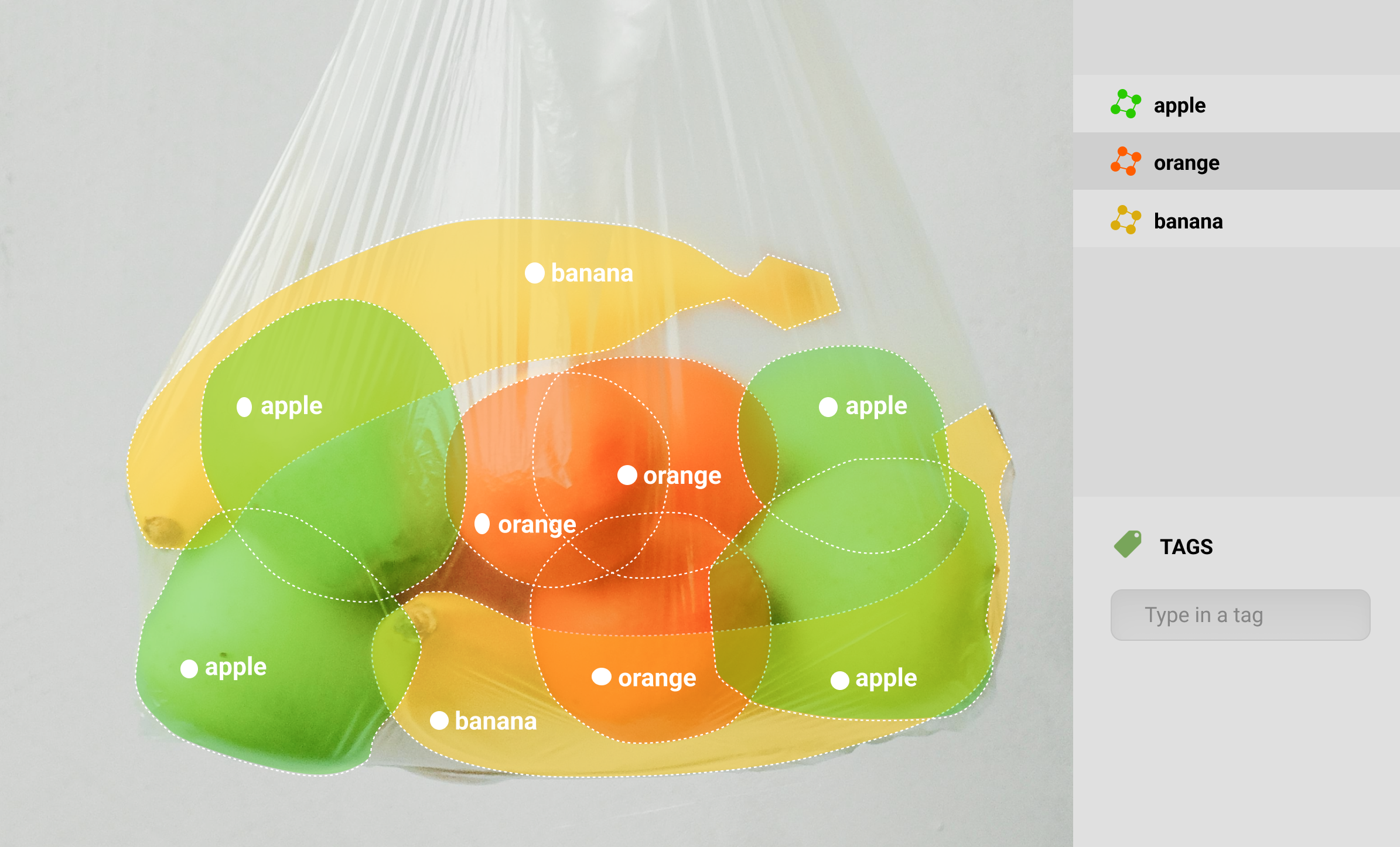
A segmentation model needs to be trained with high-quality labeling. Semantically segmented data can be used to train machine learning models to complex computer vision tasks like object detection and location. The dataset needs labels applied at the pixel level before a machine-learning model for semantic segmentation can be built. Teaching an object perception model for the natural world is the primary use of semantic segmentation, which visualizes several things belonging to the same class as a single, cohesive entity. This is an important process of creating image segmentation models, since how well the data was labeled will determine the overall quality of the end product.
Noteworthy Datasets for Dissecting Images
Large amounts of input photos are typically needed to train deep-learning models. The product of compiling and labeling photos is a dataset.Semantic segmentation requires pixel-accurate annotations, and producing them is a time-consuming and costly undertaking. Often, it makes sense to pre-annotate photos using an existing segmentation model and then employ human labor to fill in the missing predictions and rectify errors in the model. It makes sense to use edge detection and other image segmentation models to manually pre-segment the image and autofill them with the correct class label as an alternative to fully depending on the predictions given by algorithms.
Platforms for Dissecting Images
The following platforms can be used to perform high-quality semantic segmentation on your images:
-
Detectron2 – This is a very well-built library with cutting-edge detection and segmentation algorithms developed by Meta. In addition to offering simple predictions and code optimization for SOTA approaches, its structure enables users to construct their own backbones, topologies, and data loaders that are appropriate for a customized research endeavor.
- PaddlePaddle/PaddleSeg – Just like the platform mentioned above, PaddleSeg is a comprehensive, highly efficient development toolkit for image segmentation derived from PaddlePaddle. It assists researchers and developers throughout the entire segmentation and training model design process, as well as in maximizing performance and inference speed and model deployment.
Key Insights
Semantic segmentation is a fundamental task in computer vision, empowering machines with the ability to understand visual content at a granular level. With advancements in deep learning techniques and architectures, semantic segmentation continues to evolve, unlocking new possibilities across various industries and driving innovation in AI-powered solutions. As research in this field progresses, we can expect further improvements in accuracy, efficiency, and applicability, fueling the development of smarter and more capable intelligent systems.





