How to Make It Possible to Use Pre-Labeled Data for AI Algorithms With High Quality Requirements
In machine learning, data labeling is the process of identifying objects or events on raw data (images, text files, videos, etc.) and adding one or more meaningful and informative labels to provide context so that a machine learning model can learn from it. For example, labels might indicate whether a photo contains a bird or car, which words were uttered in an audio recording, or if an x-ray contains a tumor. Data labeling is required for a variety of use cases, including computer vision, natural language processing, and speech recognition.
Successful machine learning models are built on the shoulders of large volumes of high-quality annotated training data. But, the process of obtaining such high-quality data can be expensive, complicated, and time-consuming, which is why sometimes companies look for ways to automate the data annotation process. While the automation may appear to be cost-effective, as we will see later on, it also may contain some pitfalls, hidden expenses, cause you to incur extra costs to reach the needed annotation quality level as well as put your project timing at risk.
In this article, we take a closer look at the hidden risks and complexities of using pre-labeled data which can be encountered along the way of automating the labeling process and how it can be optimized. Let’s start by getting an overview of what pre-labeled data is.

What is Pre-Labeled Data?
Pre-labeled data is the result of an automated object detection and labeling process where a special AI model generates annotations for the data. Firstly the model is trained on a subset of ground truth data that has been labeled by humans. Where the labeling model has high confidence in its results based on what it has learned so far, it automatically applies labels to the raw data with good quality. Often the quality of pre-labeled data may appear to be not good enough for projects with high accuracy requirements. This includes all types of projects where AI algorithms may affect directly or indirectly the health and lives of humans.
In quite many cases, after the pre-labeled data is generated, there are doubts and concerns about its accuracy. When the labeling model has not sufficient confidence in its results, it will generate labels and annotations of the quality, which isn’t enough to train well-performing AI/ML algorithms. This creates bottlenecks and headaches for AI/ML teams and forces them to add extra iterations in the data labeling process to meet high quality requirements of the project. A good solution here will be to pass the automatically labeled data to specialists to validate the quality of annotations manually. This is why the step of validation becomes really important since it can remove the bottlenecks and give the AI/ML team peace of mind that a sufficient data quality level was achieved.
As we can see, there are some challenges companies face with pre-labeled data when the ML model was not properly trained on a particular subject matter or if the nature of raw data makes it difficult or even impossible to detect and label all edge cases automatically. Now let’s take a closer look at the potential issues companies need to be ready for if they choose to use pre-labeled data.

Pre-Labeled Data May Not Be as Cost-Effective as You Think
One of the main reasons companies choose to use pre-labeled data is the higher cost of manual annotation. While from first look it can seem like automation would lead to huge cost savings, in fact, it might not. Different types of data and various scenarios require the development and adjustments of different AI models for pre-labeling, which can be costly. Therefore, for the development of such AI models to pay off, the array of data for which it is created must be large enough to make the process of developing the model cost-effective.
For example, to develop ADAS and AV technologies, you need to consider a lot of different scenarios that include many variables and then list those factors. All of this creates a large number of combinations, each of which may require a separate pre-annotation algorithm. If you are relying on pre-labeled data to train the AI system, you will need to constantly develop and adjust algorithms that can label all of the data. It results in a significant increase in costs. The price tag of generating high-quality pre-annotations can grow exponentially depending on the variety of data used in the project, which would erase any cost savings you may obtain from hiring a dedicated annotation team. However, if the data array is really large, then the path of pre-labeling data will be fully justified, but the quality risks of these annotations still must be taken into account, and in most cases, the manual quality validation step will be necessary.
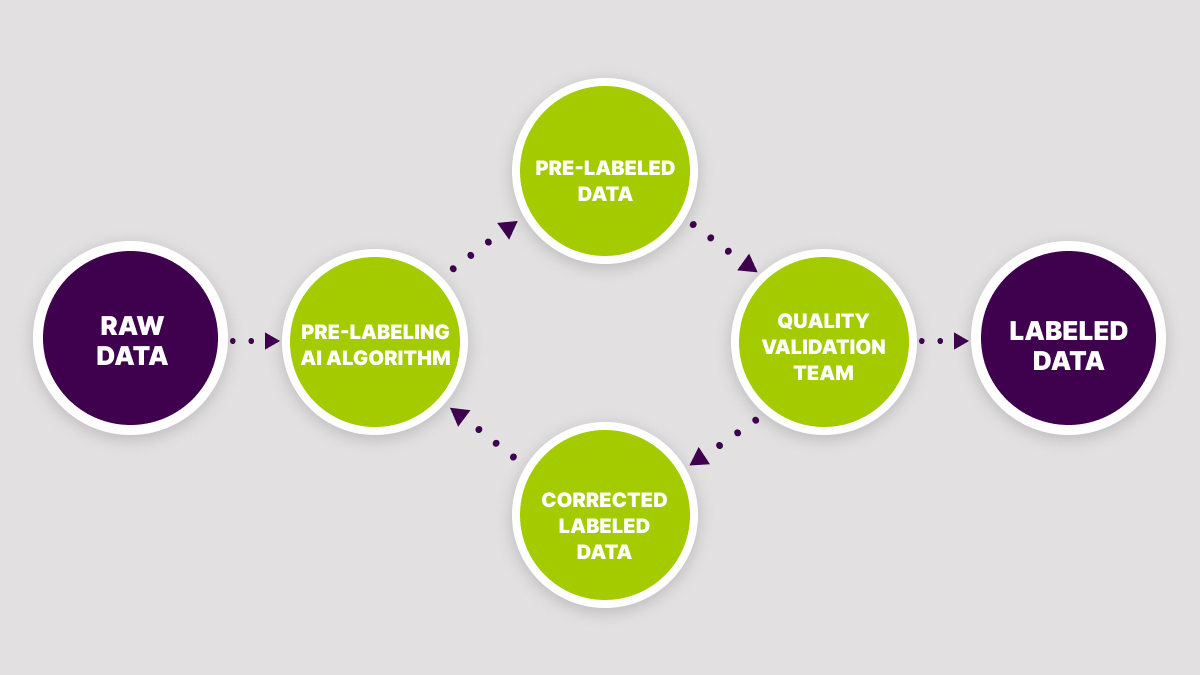
You Will Incur Data Validation Costs
In the previous section, we talked that an ML system has limited ability to learn all of the possible scenarios to label a dataset properly, which means that AI/ML teams will need a quality validation step to ensure that the data labeling was done correctly and the needed accuracy level was reached. Algorithms for data pre-annotation have a hard time understanding complex projects with a large number of components: the geometry of object detection, labeling accuracy, recognition of different object attributes, etc. The more complex the taxonomy and the requirements of the project the more likely it is to produce predictions of lower quality.
Based on the experience of our work with clients, no matter how well their AI/ML team developed the pre-annotation algorithms for cases with inconsistent data and complex guidelines, their quality is still nowhere near the quality level requirement, which usually is a minimum of 95% and can be as high as 99%. Therefore, the company will need to spend additional resources on manual data validation to maintain the high-quality data supply to ensure the ML system meets the needed accuracy requirements.
A good solution in this case will be to plan ahead the quality validation step and the resources not to put the project quality and deadline in risk, but to have the needed data available in time. Also the bottleneck can be easily eliminated by finding a reliable experienced partner who can support your team with annotation quality tasks to release the product without delays and ensure faster time-to-market.

Some Types of Data Annotations Can Only Be Done by Humans
Certain annotation methodologies are difficult to reproduce via the pre-labeling method. In general, for projects where the model may carry risks to life, health, and safety of people, it would be a mistake to rely on auto-labeled data alone. For example, if we take something relatively simple, like object detection with the help of 2D boxes, common scenarios of the automotive industry can be synthesized with sufficiently high quality. However, the segmentation of complex objects, with large unevenness of object boundaries, will usually have a rather low quality with automated annotation.
In addition to this, often there is a need for critical thinking when annotating and categorizing certain objects, as well as scenarios. For example, landmarking of human skeletons can be synthesized, and over the course of training and refinement of the algorithm, the quality of pre-annotations can be satisfactory. However, if the project includes data with a large number of different poses, as well as occluded objects with a need to anticipate key points for labeling, for such annotation, critical thinking will be necessary to achieve a high-quality level. Even the most advanced algorithms today and in the near future will not have critical thinking, so such a process is possible only through manual annotation.
Trust Mindy Support With All of Your Data Annotation and Quality Validation Needs
Mindy Support understands the importance for companies of cost-saving through pre-labeling as well as the need to eliminate risks in projects where there is a heightened requirement for quality. For almost a decade we support businesses in their development of the most sophisticated AI solutions by taking the burden of data annotation and quality validation tasks off their shoulders.
Mindy Support is a global company for data annotation and business process outsourcing, trusted by several Fortune 500 and GAFAM companies, as well as innovative startups. With nine years of experience under our belt and offices and representatives in Cyprus, Poland, Romania, The Netherlands, India, and Ukraine, Mindy Support’s team now stands strong with 2000+ professionals helping companies with their most advanced data annotation challenges.





