Unlocking the Power of Unlabeled Data in Machine Learning
In the realm of machine learning, data is often considered the fuel that drives models to achieve remarkable feats of intelligence. Traditionally, labeled data, where each input is accompanied by a corresponding output, has been the primary focus of training machine learning algorithms. However, the world is replete with vast amounts of unlabeled data – information that lacks explicit data annotation or categorization. Leveraging this unlabeled data effectively presents a tantalizing opportunity for advancing machine learning capabilities. We’ll explore the significance of unlabeled data, techniques for utilizing it, and the potential it holds for enhancing machine learning systems.
In this article, we will take a look at labeled and unlabeled data and how you can use the latter to power your machine-learning projects.
What is Labeled and Unlabeled Data in Machine Learning?
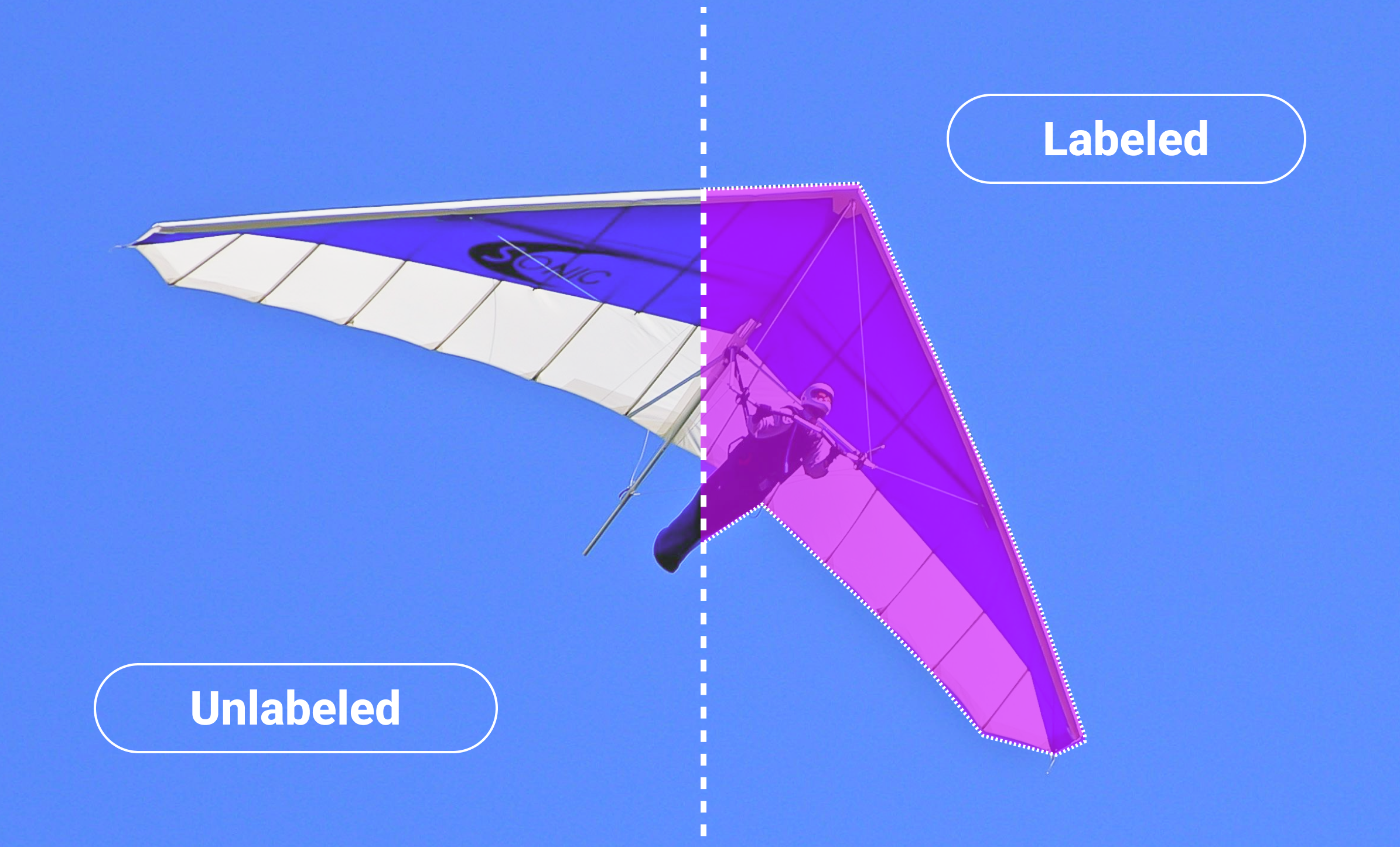
Unlabeled data refers to raw information that lacks explicit tags or annotations. Unlike labeled data, which provides clear indications of what each data point represents, unlabeled data is devoid of such information. This can include unstructured text, raw sensor readings, images, or any other form of data that has not been categorized or labeled. On the other hand, data that has been given one or more labels to provide context or meaning is referred to as labeled data. These labels are frequently used in artificial intelligence and machine learning as a target for the algorithm to predict. Labeled data is essential because it serves as the foundation for supervised learning, a well-liked method for developing machine learning models that are more precise and efficient.
Now that we know the difference between labeled data and unlabeled data in machine learning, let’s compare the two in terms of which one is more beneficial.
Battle of Annotation: Labeled vs Unlabeled Data
Both labeled and unlabeled data in machine learning have their benefits depending on the use cases. More specifically, the decision will be based on whether you are working on a supervised or unsupervised machine learning project. Our overview of what labeled data and unlabeled data are in the previous section will help you here, but the basic features of the input data can be found by unsupervised learning and used to inform supervised learning. If the labeled data is sufficiently representative of the combined data, this can be used to enrich labeled training data with unlabeled data so that cluster proximity gives valid label assignments. In the next section, we will take a closer look at supervised and unsupervised machine learning models.
Main Types of Machine Learning Models
In addition to knowing what is the difference between labeled and unlabeled data, you also need to know about the main types of machine learning models:
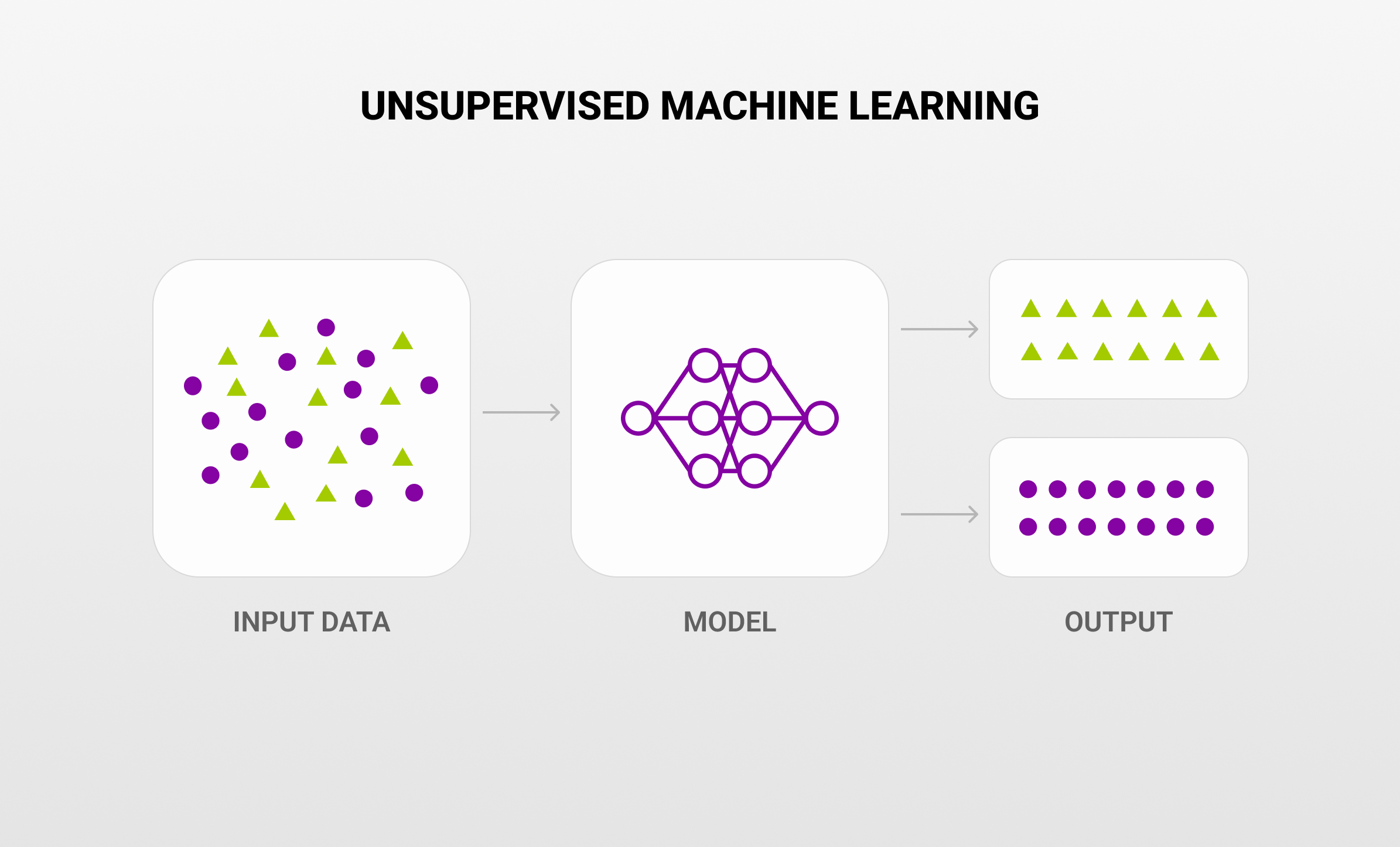
- Unsupervised machine learning – These models evaluate and cluster unlabeled datasets using machine learning algorithms. These algorithms find hidden relationships or patterns in the data without requiring human assistance.
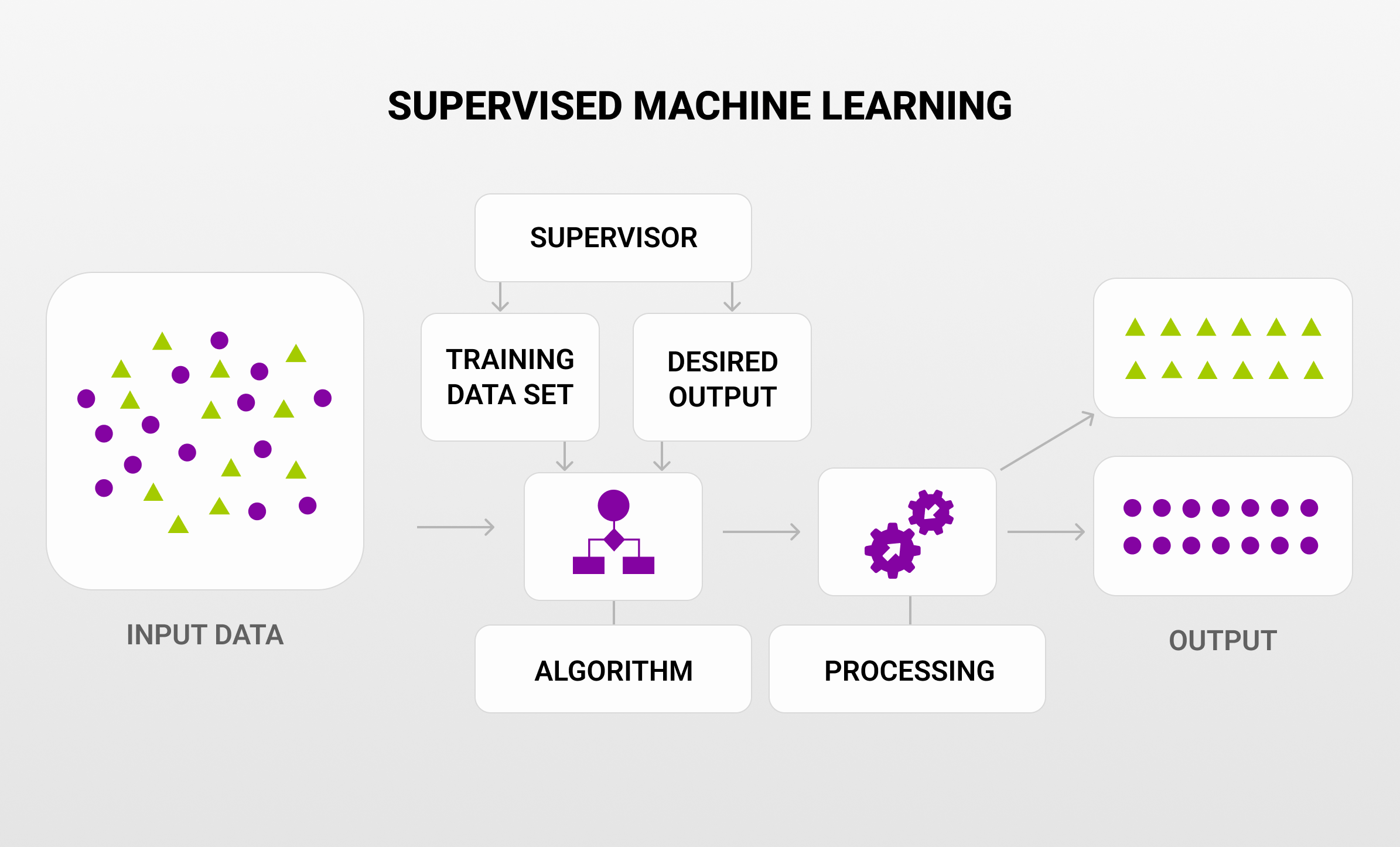
- Supervised machine learning – Supervised learning involves using labeled datasets to train algorithms for pattern recognition and result prediction. Supervised learning algorithms receive labeled training to understand the connection between the input and the outputs, in contrast to unsupervised learning.
- Between supervised and unsupervised learning, there is a kind of machine learning called semi-supervised learning. It’s a technique that trains a model with a lot of unlabeled data and a small amount of annotated data.
- Reinforcement machine learning – Using this method, software is trained to make judgments that will produce the best outcomes. It emulates how humans learn by making mistakes and trying again until they reach their objectives.
- Both labeled and unlabeled data may be needed, depending on the requirements of your project. We already covered what is labeled data and the difference between labeled and unlabeled data, but when do you use unlabeled data? We explore this in the next section.
Unsupervised Machine Learning: Why Use Unlabeled Data
One of the biggest reasons to use unlabeled data is that it allows you to leverage a couple of important techniques:
- Clustering – This is an unsupervised learning technique that sorts elements according to proximity in measurement space. Clustering is a popular technique in unsupervised learning applications nowadays because it doesn’t require training data labels. Either stand-alone techniques, like the k-means algorithm, or parameter optimization within an ML system can be used to achieve this.
- Dimensionality reduction – The technique of extracting as much information as feasible from a dataset while lowering its feature count. This can be used to simplify a model, enhance a learning algorithm’s functionality, or facilitate data visualization.
Semi-Supervised Machine Learning: When You Have Both Labeled and Unlabeled Data
If you are working on a semi-supervised machine learning project, you may be able to use both labeled and unlabeled data to leverage methods such as:
- Clustering – When labeled data is available, a machine learning technique called semi-supervised clustering can improve clustering performance. In fact, real-world use cases typically contain some labeled data that can be used to start the clustering process, guide it, and improve its efficiency.
- Adversarial training with unlabeled data – Semi-supervised learning models can use unlabeled data, but this may lead to a decline in the performance of the learned model due to the bias in the estimation of labels for unlabeled data. To mitigate this issue, you will need to create a framework that treats the unlabeled samples as both positive and negative ones, which allows us to avoid guessing labels for unlabeled data.
Conclusion
Unlabeled data represents a vast and largely untapped resource in the field of machine learning. By leveraging advanced techniques such as semi-supervised learning, unsupervised learning, and generative modeling, researchers and practitioners can extract valuable insights and improve the performance of machine learning models as the volume of unlabeled data continues to grow exponentially, unlocking its potential promises to usher in a new era of innovation and discovery in artificial intelligence.
FAQs
1. What is labeled and unlabeled data?
Unlabeled data is utilized in unsupervised learning and lacks additional information, whereas labeled data has relevant tags and is used in supervised learning. The process of labeling is necessary for labeled data, whereas unlabeled data is essentially unprocessed data prior to labeling.
2. How to tell what is in an unlabeled can?
Basically, these are data points that lack labels designating their attributes, qualities, or classifications. Unlabeled data just contains features to represent them; it lacks labels or targets to predict.
3. What is the difference between labeled and unlabeled data?
Unlabeled data refers to any data that lacks labels indicating its traits, identification, classification, or other attributes. Labeled data is any data that has an attribute, category, or characteristic attached to it.





