Reading Between the Pixels: Exploring the World of OCR
Optical Character Recognition, commonly known as OCR, is a transformative technology that has revolutionized the way we interact with printed and handwritten texts. This fascinating technology converts different types of documents, such as scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data. Let’s dive into what OCR is and how it works, shedding light on its underlying mechanisms and applications, as well as the data annotation needed to make this technology work.
What is OCR?

At its core, Optical Character Recognition is a technology that recognizes text within a digital image. OCR is widely used to digitize printed texts so that they can be edited, searched, stored more compactly, displayed online, and used in machine processes such as cognitive computing, machine translation, (extracted) text-to-speech, key data, and text mining. OCR is a bridge between the physical and the digital world, turning analog information into digital data.
How Does OCR Work?
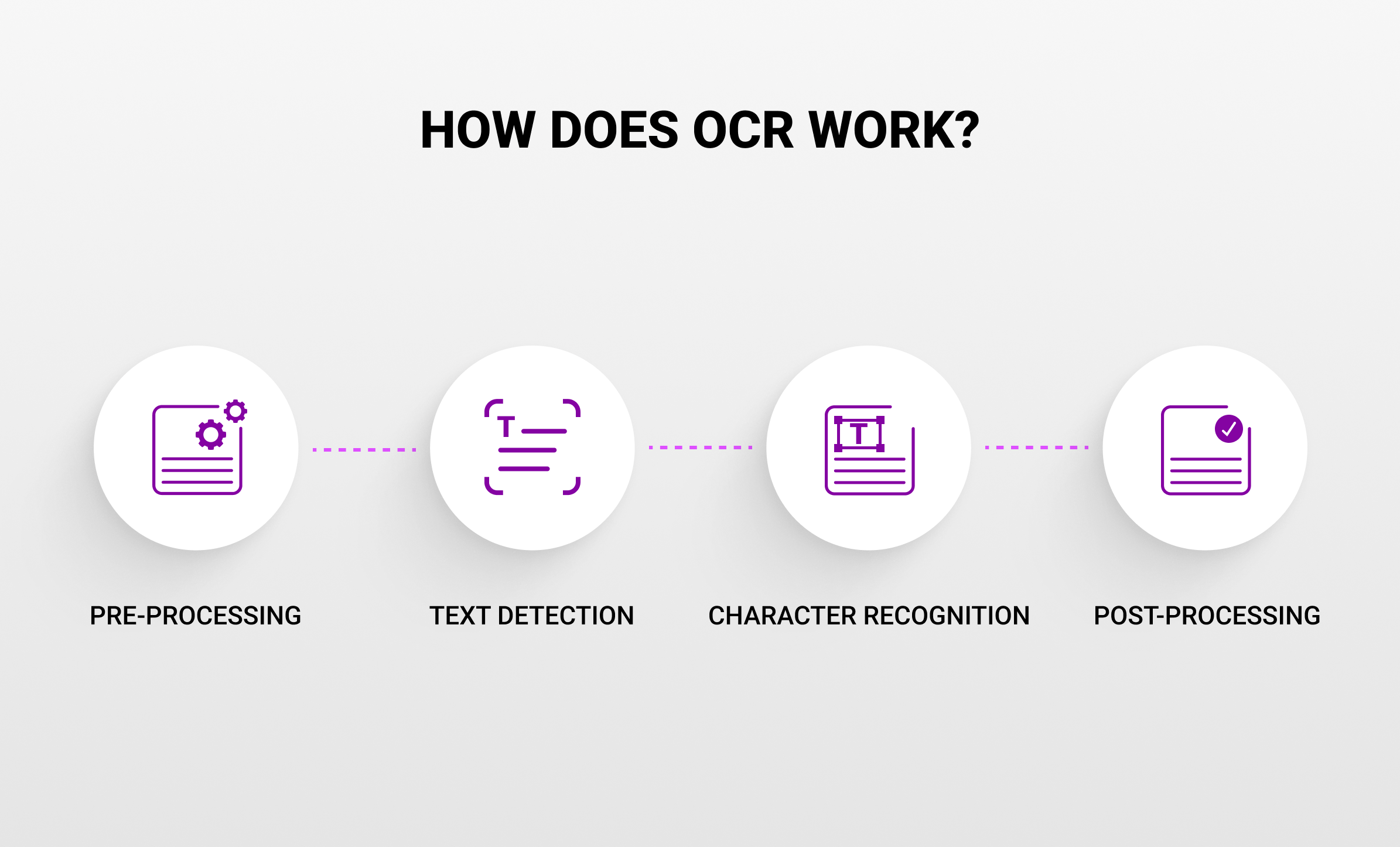
The process of Optical Character Recognition involves several stages, from pre-processing the image to recognizing characters and post-processing the text. Here’s a simplified breakdown of how it works:
Pre-processing
This initial phase is crucial for improving the accuracy of the OCR process. It involves cleaning up the image to make it easier for the OCR software to read the text. Pre-processing may include steps such as adjusting the image brightness and contrast, removing noise, correcting skew (angle), and segmenting the image into lines, words, or characters.
Text Detection
Once the image is pre-processed, the OCR software proceeds to detect areas of the image that contain text. This involves distinguishing text from images, backgrounds, or any other non-textual elements. Modern OCR systems can detect text in various fonts and formats, even identifying handwritten notes, though with varying degrees of success.
Character Recognition
This is the heart of the OCR process, where the software interprets each character within the text. Early OCR systems relied on template matching, where scanned characters were compared to a predefined set of character templates. Modern OCR technologies, however, use more sophisticated methods such as feature detection and neural networks. These methods allow the system to recognize characters by analyzing their features (such as lines, loops, and intersections) and patterns, making it possible to understand a wide variety of fonts and handwriting styles.
Post-processing
After the characters are recognized, the OCR software may perform post-processing to improve the accuracy of the text. This can involve checking the text against a dictionary to correct any errors, or using language models to make educated guesses about ambiguous characters. The result is a digital text file that closely matches the original printed or handwritten document.
OCR Algorithms
OCR algorithms are the underlying computational processes that enable software to convert images of typed, handwritten, or printed text into machine-encoded text. These algorithms are the brains behind OCR technology, allowing computers to recognize and process characters from images or scanned documents. The development and sophistication of OCR algorithms have evolved significantly, leveraging advancements in artificial intelligence (AI), machine learning (ML), and computer vision. Here’s a closer look at the various types of OCR algorithms and how they function.
Some of the most popular OCR algorithms are:
- Image processing and CNNs– Image processing is the first critical step in the OCR pipeline, preparing images for more efficient and accurate text recognition. CNNs are a class of deep neural networks most commonly applied to analyzing visual imagery. They are exceptionally well-suited for image recognition tasks, including OCR, because of their ability to automatically and adaptively learn spatial hierarchies of features from images.
- Transformers – Transformers are based on the self-attention mechanism, allowing the model to weigh the importance of different parts of the input data differently. The application of Transformers in OCR leverages this capability to not just recognize individual characters or words but also understand text in the context of the whole document. This is particularly useful for documents where layout and formatting convey meaning, such as invoices, forms, and scientific papers.
Advantages and Limitations of OCR

Like any technology, OCR comes with its own set of advantages and limitations. Understanding these can help determine the most effective use cases for OCR technology and identify areas for further development and improvement. The advantages of OCR include:
- Efficiency and Speed – OCR significantly speeds up the process of converting physical documents into digital formats. It eliminates the need for manual data entry, which can be time-consuming and prone to errors. With OCR, vast amounts of text can be digitized and processed in a fraction of the time it would take to do so manually.
- Searchability and Accessibility – Once text has been converted into digital form, it becomes easily searchable. This is particularly useful in managing large databases of documents, where finding specific information quickly can be crucial. Digital text can also be easily accessed by people with disabilities using screen readers and other assistive technologies.
- Cost Savings – By automating the data entry process, organizations can save on labor costs associated with manual transcription. Additionally, digital documents require less physical storage space, reducing costs related to filing, archiving, and retrieving paper documents.
The following are the challenges of OCR:
- Quality of source material – The accuracy of OCR is heavily dependent on the quality of the source material. Poorly printed, handwritten, or damaged documents can significantly decrease the effectiveness of OCR technology, leading to errors in the digitized text.
- Complex layouts and fonts – Documents with complex layouts, multiple fonts, or decorative elements can pose challenges for OCR systems. While advanced algorithms have improved the handling of such documents, issues may still arise, affecting the accuracy and completeness of the digitization.
- Language and character limitations – Early OCR systems were primarily designed for English text and common fonts. Though this has improved, some OCR systems may still struggle with less common languages, scripts, or specialized terminology, requiring further development and customization.
Use Cases

The use cases of OCR technology are vast and varied, touching nearly every industry. Some notable applications include:
- Preservation of documents – OCR offers an effective solution for converting historical and archival documents into digital formats. This digitization process not only helps in safeguarding the content of aging and fragile documents against physical degradation but also makes these invaluable resources more accessible to researchers, scholars, and the public.
- Banking and finances – By automating the data extraction process from various paper-based documents such as checks, bank statements, and customer identification documents, OCR significantly reduces processing times and errors associated with manual data entry.
- License plate recognition – OCR allows for the automatic detection and reading of vehicle license plates from images or video streams and facilitates real-time processing and identification of vehicles without manual intervention. This capability is crucial for applications such as automated toll collection, traffic law enforcement, parking access control, and security monitoring at sensitive sites.
- Text-to-speech – By scanning and analyzing text from various sources such as books, documents, or digital screens, OCR extracts the textual content and translates it into a format that TTS engines can interpret and vocalize. This process enables individuals with visual impairments or reading difficulties to access printed or digital information through audio output.
Which Industries Use OCR?

OCR can be useful for companies in the following industries:
- Banking and Finance – OCR is used for automating data extraction from checks, invoices, receipts, and financial documents, speeding up transaction processing, and improving accuracy in record-keeping and compliance.
- Transportation and Logistics – In logistics and transportation, OCR is employed for automating package tracking, scanning shipping labels, and managing documentation such as bills of lading, reducing errors and improving efficiency.
- Legal – Legal professionals use OCR to convert physical documents, contracts, court records, and case files into searchable digital formats, enabling faster retrieval of information and enhancing collaboration.
- Education – OCR aids in digitizing textbooks, research papers, and educational materials, making them accessible to students with visual impairments and enabling advanced search and analysis capabilities.
- Retail and E-commerce – OCR is utilized for automating inventory management, scanning product labels, receipts, and invoices, and extracting information for pricing, cataloging, and supply chain optimization.
Automating OCR With Mindy Support
Mindy Support can help you automate data annotation for OCR to streamline document processing workflows, reducing manual effort and increasing efficiency. We can help you:
- Identify document sources and types – This includes determining the sources of documents to be processed, such as scanned images, PDF files, or digital photos. We can also identify the types of documents, including invoices, receipts, forms, or handwritten notes, as different types may require different OCR approaches.
- Maintain data security and compliance – Our teams can regularly audit your data annotation automation processes to ensure compliance and mitigate potential risks. We have strict security measures in place to protect sensitive data processed by OCR, including encryption, access controls, and compliance with data privacy regulations such as GDPR and other laws.
- Data collection – We can gather a diverse dataset of images containing text that represents the range of scenarios your OCR system will encounter. This dataset should include images with various fonts, sizes, orientations, backgrounds, and languages.
Final Thoughts
Despite its advances, OCR technology still faces challenges, particularly with recognizing handwriting, stylized fonts, or text in cluttered images. The ongoing development in machine learning and artificial intelligence, however, continues to push the boundaries of what OCR can achieve, promising ever-greater accuracy and versatility.
In conclusion, OCR is a pivotal technology in our digital age, transforming the way we handle and interact with text. As OCR technology evolves, it will undoubtedly continue to play a critical role in various fields, making information more accessible and workflows more efficient.





