What is Panoptic Segmentation and How It Works
Panoptic segmentation is an advanced computer vision technique that combines the strengths of semantic and instance segmentation to provide a comprehensive understanding of visual scenes. Unlike traditional segmentation methods that either classify each pixel into a category (semantic segmentation) or identify individual objects (instance segmentation), panoptic segmentation unifies these tasks, offering a complete picture where every pixel in an image is labeled with both its semantic class and object identity.
This technique has become crucial in fields like autonomous driving, robotics, and medical imaging, where precise and detailed scene understanding is essential. In this article, we will explore the panoptic segmentation meaning, how it works, and its significance in modern computer vision.
Essentials of Panoptic Image Segmentation

Panoptic segmentation is an essential concept in computer vision that addresses the need for a unified approach to scene understanding. It merges the capabilities of semantic segmentation, which labels every pixel of an image according to its category, with instance segmentation, which differentiates between distinct objects of the same class. The result is a holistic segmentation framework that not only identifies the category of every pixel but also distinguishes between different instances within those categories. This dual functionality makes panoptic segmentation particularly valuable in complex environments, where understanding both the types of objects present and their specific identities is crucial.
The core of panoptic segmentation lies in its ability to generate a panoptic segmentation map, which consists of two key components: a semantic segmentation map and an instance segmentation map. The semantic map provides class labels for all pixels, while the instance map assigns unique IDs to pixels belonging to the same object instance. The combination of these maps allows for a detailed and coherent understanding of a scene, where both “stuff” (amorphous regions like sky, grass, or road) and “things” (countable objects like cars, people, or animals) are accurately represented. This approach enhances the precision of tasks in areas such as autonomous driving, where it’s vital to not only detect pedestrians but also distinguish between them, or in medical imaging, where separating overlapping anatomical structures is key.
Distinctive Features: Panoptic Segmentation vs Instance Segmentation

Panoptic segmentation and instance segmentation are both important techniques in computer vision, but they serve slightly different purposes and have distinct characteristics:
Scope of Segmentation
- Instance Segmentation: Focuses exclusively on “things,” which are countable objects like cars, people, or animals. It identifies and separates each instance of these objects in an image, assigning a unique label to each one.
- Panoptic Segmentation: Combines instance segmentation with semantic segmentation. It segments both “things” and “stuff” (amorphous regions like sky, grass, or road). Efficient panoptic segmentation provides a complete labeling of every pixel in the image, addressing both object instances and general regions.
Output Representation
- Instance Segmentation: Produces a set of masks, each corresponding to a different object instance. These masks overlap in some cases, as multiple instances of the same category can appear in the same area of the image.
- Panoptic Segmentation: Outputs a single unified map where each pixel is assigned a unique label that combines semantic class information with instance identity. This map ensures that there is no overlap; each pixel belongs to only one segment, either a specific instance or a general region.
Application Focus
- Instance Segmentation: Is particularly useful when the primary goal is to detect and differentiate between individual objects of the same type, such as identifying all cars in a street scene or all cells in a microscope image.
- Panoptic Segmentation: Is used when a more comprehensive understanding of the scene is required. It’s important in scenarios where both object detection and contextual information about the environment are needed, such as autonomous driving or robotic navigation.
The Mechanism Behind Panoptic Segmentation
The mechanism behind panoptic segmentation involves a sophisticated integration of semantic and instance segmentation techniques to achieve comprehensive scene analysis. The process typically begins with separate networks or a unified architecture that handles the segmentation tasks: one part of the model focuses on semantic segmentation, assigning a class label to every pixel, while another part handles instance segmentation, identifying and distinguishing individual objects within those classes.
These outputs are then combined to create a panoptic segmentation map, where each pixel is uniquely labeled with both its category and, if applicable, its specific object instance. A critical step in this process is resolving overlaps between instance segments and ensuring that every pixel is consistently classified, which is often managed by a post-processing step that merges the semantic and instance maps into a seamless, unified output. This approach allows panoptic segmentation to provide a full understanding of both the objects present in a scene and their contextual relationships, enabling more nuanced and effective interpretations of visual data.
Innovations in Panoptic Segmentation Models
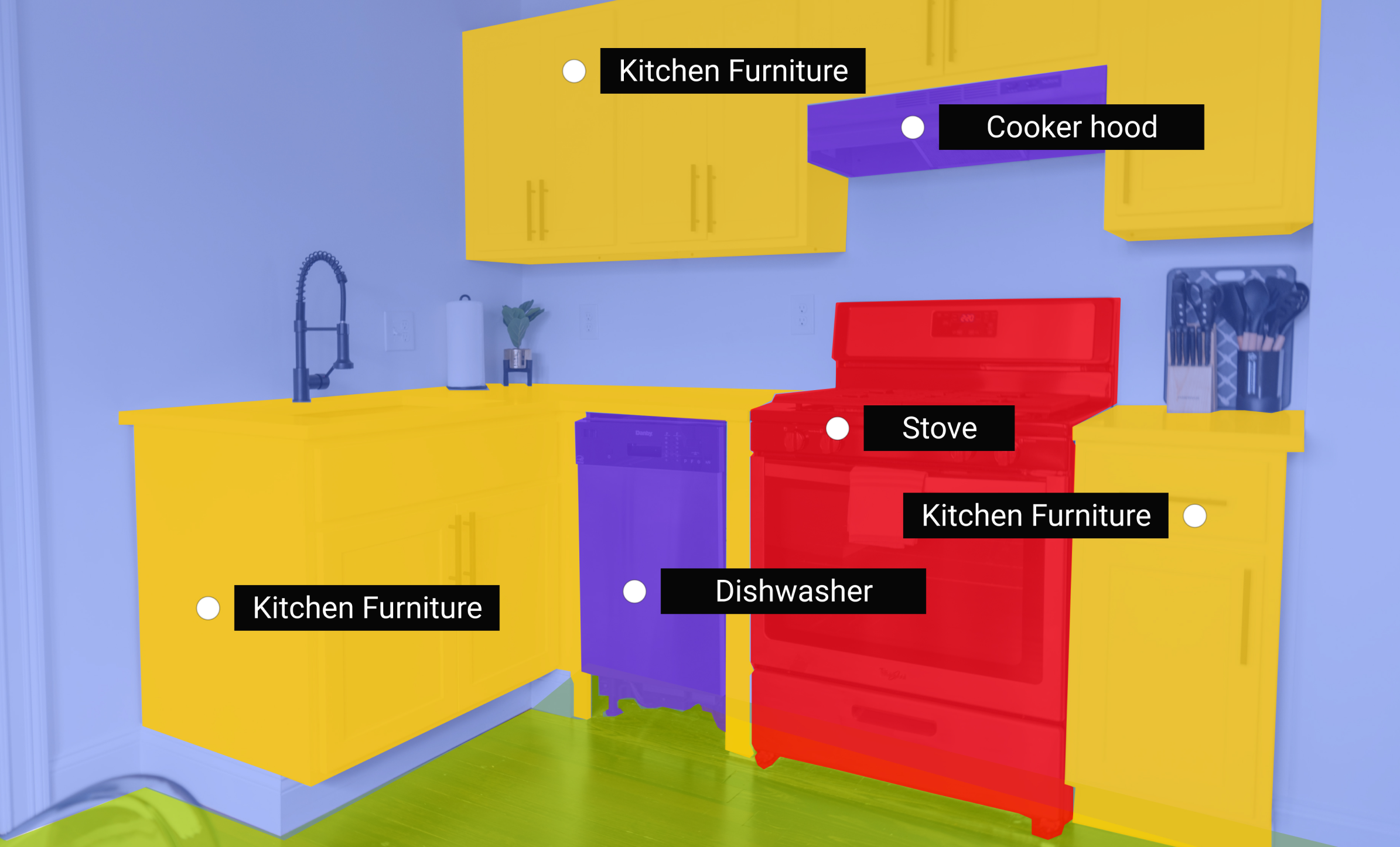
Innovations in panoptic segmentation models have significantly advanced the accuracy and efficiency of scene understanding in computer vision. Recent developments include the creation of unified architectures that streamline the segmentation process by simultaneously performing semantic and instance segmentation within a single network, reducing computational complexity. Techniques like the Panoptic Feature Pyramid Network (PFPN) enhance the model’s ability to capture multi-scale features, improving the accuracy of segmenting both small and large objects.
Additionally, innovations in loss functions and training strategies, such as the use of panoptic quality (PQ) as a metric, have driven more precise and consistent model performance. Advances in attention mechanisms and transformer-based models have further enhanced the ability to handle complex scenes with diverse objects and backgrounds, pushing the boundaries of what panoptic segmentation can achieve in real-world applications like autonomous driving, robotics, and augmented reality.
Real-World Utilization of Panoptic Segmentation

Panoptic segmentation has found extensive real-world applications across various industries, significantly enhancing the capabilities of systems that rely on detailed scene understanding. In autonomous driving, it is crucial for accurately identifying and distinguishing between pedestrians, vehicles, road signs, and the surrounding environment, ensuring safe navigation in complex urban settings. In robotics, panoptic segmentation enables robots to interact more intelligently with their surroundings by recognizing and categorizing objects and spaces, facilitating tasks such as object manipulation and environment mapping.
In the realm of medical imaging, it helps in the precise segmentation of anatomical structures, aiding in diagnostics and surgical planning. Moreover, panoptic segmentation is increasingly used in augmented reality (AR) to overlay digital content on real-world scenes with greater accuracy, enhancing user experiences in gaming, education, and remote assistance. Its ability to provide a holistic and detailed understanding of scenes makes panoptic segmentation a pivotal technology in advancing these cutting-edge applications.
Overcoming Obstacles in Panoptic Segmentation
Overcoming obstacles in panoptic segmentation requires addressing the inherent complexities of integrating semantic and instance segmentation into a single, cohesive framework. One of the primary challenges is managing the precise differentiation of objects that overlap or exist in close proximity, especially when they belong to the same category. This difficulty is compounded by the need to simultaneously assign accurate semantic labels to every pixel in the scene, which demands sophisticated post-processing techniques and advanced loss functions that can reconcile the sometimes conflicting goals of the two segmentation tasks.
Additionally, ensuring that the segmentation model performs effectively across diverse object scales and image resolutions presents another significant hurdle. Smaller objects, in particular, are prone to being missed or incorrectly segmented, necessitating the use of multi-scale feature extraction methods and specialized architectures that can capture both fine-grained and large-scale details. Through ongoing research and the development of innovative solutions, such as enhanced feature pyramids, attention mechanisms, and efficient network designs, these obstacles are being systematically overcome, paving the way for a more robust and accurate panoptic segmentation model.
The Future Landscape of Panoptic Segmentation
The future landscape of panoptic segmentation promises to be marked by continued advancements in both accuracy and efficiency, driven by innovations in deep learning and computer vision. As research progresses, we can expect the development of more sophisticated models that seamlessly integrate semantic and instance segmentation with greater precision, even in highly complex scenes with numerous overlapping objects and varied backgrounds. Emerging technologies like transformer-based architectures and self-supervised learning are likely to play a significant role in enhancing the capabilities of panoptic segmentation, allowing models to generalize better across diverse environments and reducing the reliance on large labeled datasets.
Real-time panoptic segmentation is expected to become more feasible, enabling its broader adoption in applications such as autonomous vehicles, robotics, and augmented reality, where quick and accurate scene understanding is critical. As these technologies mature, panoptic segmentation will become an even more integral part of systems that require detailed and holistic scene interpretation, pushing the boundaries of what’s possible in artificial intelligence and machine perception.
Summarizing Panoptic Segmentation’s Impact
Panoptic segmentation has had a transformative impact on the field of computer vision, enabling a more comprehensive and nuanced understanding of visual scenes. By merging semantic and instance segmentation into a unified framework, it allows for the precise labeling of every pixel in an image, distinguishing between individual objects while also capturing the broader context of the scene. This dual capability has significantly enhanced the accuracy and functionality of applications ranging from autonomous driving and robotics to medical imaging and augmented reality, where detailed scene interpretation is crucial. The advancements in panoptic segmentation have not only improved the performance of these systems but also expanded the possibilities for future innovations in artificial intelligence, making it a cornerstone technology in the ongoing evolution of machine perception.
Discover Our Advanced Segmentation Solutions
Mindy Support helps you unlock the power of precision of AI solutions with our advanced semantic segmentation and other data annotation services. We specialize in providing meticulous and high quality annotations for images, videos, and text, ensuring your machine learning models receive the high-quality data they need to thrive. Trust us with all of your data annotation needs.





