What is Data Annotation and why does it play a role in the success of your LLM Project?
Data annotation refers to the process of categorizing or marking data to ready it for use, in machine learning and artificial intelligence systems. This task involves pinpointing. Highlighting elements within the data, such as text, images, audio and video to construct a well organized dataset. These annotations enable models to identify patterns and make predictions by establishing a reference point for training and validation. Depending on the complexity and volume of data annotation can be done manually by annotators or through automated software tools to help LLM prompt engineering and other processes.
In this article we will take a look at what is a large language model and some data annotation methods used to train these algorithms. The quality of data annotation greatly influences the accuracy and performance of machine learning models since it directly affects their ability to learn from labeled examples.
Importance of Quality Data for LLMs

This leads us to our query: what exactly constitutes a language model? Large Language Models (LLMs) utilize algorithms and neural networks to comprehend, generate and manipulate language. These models are trained on amounts of text information that empower them to execute tasks, like translation, summarization, question answering and engaging in conversations by predicting and producing coherent text that is contextually relevant based on input cues.
The importance of having high quality data, for LLM artificial intelligence cannot be overstated. Quality data is crucial for training intelligence models like LLMs as it directly impacts their performance, accuracy and reliability. When the model is trained on accurate and representative data it can better grasp the nuances and subtleties of language. On the contrary, poor data quality can introduce biases, inaccuracies and gaps in the model’s understanding leading to outputs and predictions. Therefore ensuring data curation through cleaning, annotation and validation processes is essential for building robust and reliable LLM prompt engineering. This foundational step in LLM data training is fundamental for enabling these models to excel across tasks and domains ultimately enhancing their utility and user satisfaction.
The Process of Data Annotation
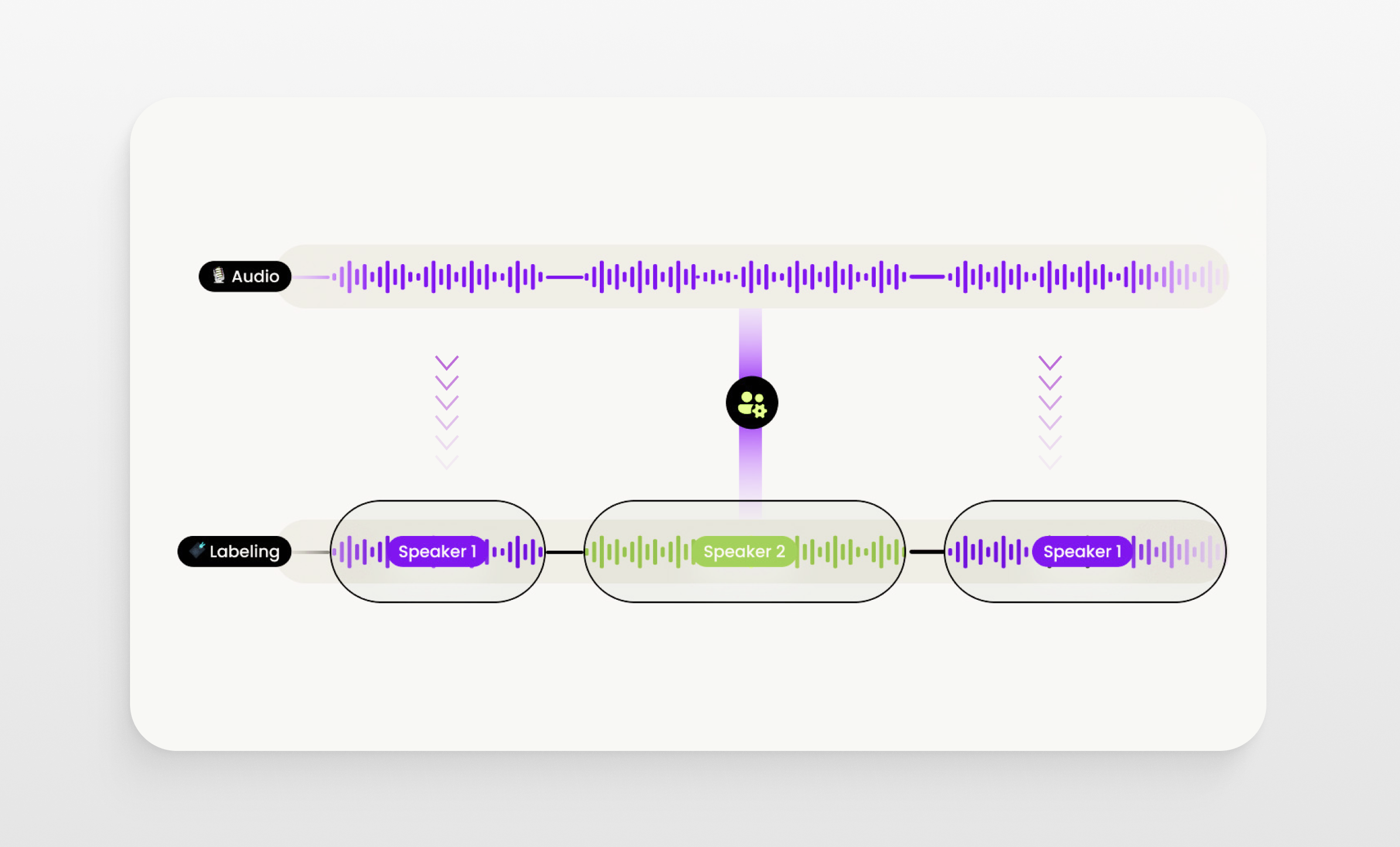
Understanding the process of data annotation is important since it is one of the challenges and applications of large language models. Data annotation involves a series of steps aimed at creating quality labeled data, for machine learning models. The process typically begins with defining objectives and guidelines for the annotation project to maintain consistency and accuracy throughout the labeling process. Subsequently raw data is collected to undergo the annotation process.This may involve text, images, audio, video or other forms of data that are pertinent to the project. Below is an overview of how data annotation works:
- Data Preparation – Process the data to eliminate any disruptive information that could impede the annotation process.
- Annotator Training – Educate human annotators on the guidelines. How to use annotation tools so they grasp the task and can execute it accurately.
- Quality Control – Review annotations from annotators utilize automated validation tools. Conduct random checks by experts to detect and rectify any mistakes or discrepancies.
Accurate and structured annotations play a role in training machine learning models as they offer the essential ground truth for recognizing patterns and making predictions. This presents a challenge and application for language models. Precision annotations ensure that models can adapt well to data thereby enhancing their reliability, performance and versatility across various tasks and domains.
Improving Model Precision and Effectiveness
LLM Data annotation enhances LLM precision by providing relevant labeled instances for the model to learn from. This enables it to comprehend language patterns effectively. Top notch annotations assist the model in capturing context semantics and subtleties better resulting in coherent outcomes, across diverse language tasks.
Quality data labeling plays a role in the efficiency and speed of training machine learning models. Precise and well organized annotations help models learn quickly and effectively reducing the need for retraining. This results in development cycles and faster iterations allowing models to achieve performance with fewer training sessions. Properly annotated data also reduces the risk of overfitting, helping identify features to optimize resources. Efficient data labeling does not improve model accuracy. Also simplifies the overall training process, saving time and costs in creating reliable machine learning solutions.
Different Techniques for Data Labeling

Techniques for annotating data for machine learning. These include:
- Text Labeling – Involves tagging text with relevant labels, like named entities (e.g. people organizations, locations) parts of speech, sentiment analysis or intent detection. Methods include named entity recognition (NER) sentiment analysis and part of speech tagging.
- Image Labeling – This method entails marking images to recognize objects, boundaries or characteristics within data. Common approaches include bounding boxes, segmentation, keypoint labeling and polygonal segmentation to capture object shapes.
- Audio Labeling – An important aspect of working with data is the process of identifying and tagging components like speech sections, speaker identities, emotions and phonetic elements. Techniques such as transcription, speaker recognition and emotion labeling are used to enhance the accuracy of speech recognition systems and audio analysis models.
- Video Labeling – This task involves assigning labels to frames in a video to monitor objects, activities or occurrences over a period. Methods like object tracking, action identification and event detection are employed to provide a context and enhance the performance of video analysis models.
- Annotation of 3D Point Clouds – Utilized in fields like driving and robotics, this method focuses on marking 3D point cloud data to recognize objects, areas and structures in three spaces accurately. Approaches such as 3D bounding boxes, semantic segmentation and instance segmentation are utilized to capture the characteristics of the data.
The data annotation process will be created and perfected based on the needed techniques and specific project requirements.
Future Developments in Data Annotation for LLMs
Upcoming trends, like supervised learning and active learning as well as model training for data annotation are reshaping the landscape of data annotation by boosting efficiency and reducing reliance on extensive labeled datasets. Semi supervised learning involves combining a set of labeled data with a pool of unlabeled data to enhance model accuracy and generalization. This strategy minimizes annotation efforts while maintaining performance levels.
Active learning in contrast entails training in which the model recognizes and asks for labels, for the enlightening and uncertain data points. By concentrating on these samples active learning reduces the need for annotations. Speeds up the learning journey. These methods are collectively enhancing the scalability and cost efficiency of data annotation facilitating effective model advancement.





