Using Panoptic Segmentation to Train Autonomous Vehicles
Like many other AI technologies, autonomous vehicles rely on annotated datasets to train the machine learning algorithms to perform a certain task. These training datasets are usually images and videos that are then annotated with methods like tagging, 2D/3D boxes, semantic segmentation, and polygons. However, recently Tesla’s Director of Artificial Intelligence, Andrej Karpathy, shared some interesting news about a project his team is working on which involves an interesting type of data annotation called panoptic segmentation.
Let’s take a closer look at the project itself and exactly what panoptic segmentation is.
What New Project is Tesla Working On?
On November 30th, Andrej Karpathy sent out the following Tweet:
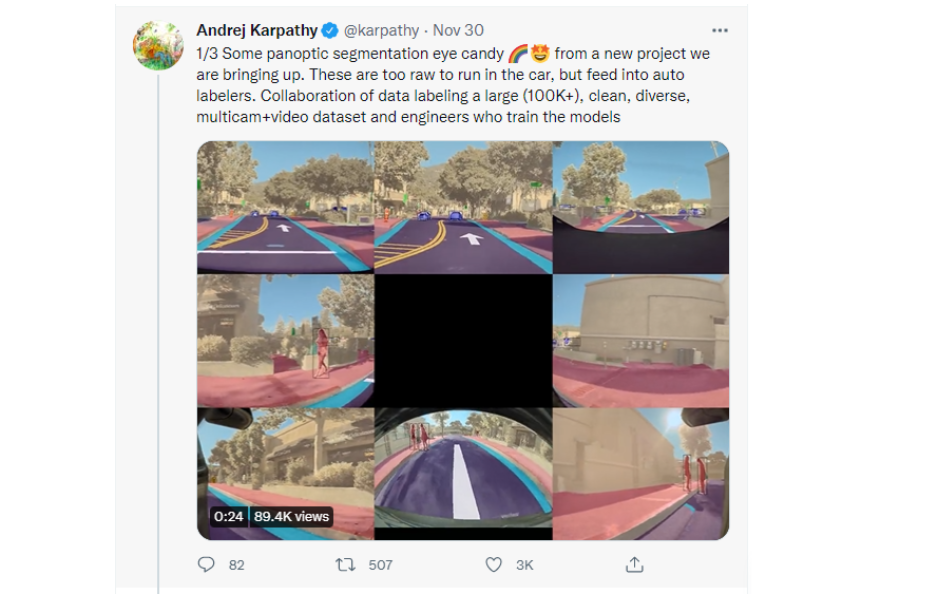
To put this in plain terms, Andrej Karpathy is looking for people who can help Tesla cluster together parts of an image/video that belong to the same object class and then get it labeled. Once this part is done, the goal will be to improve the system more and more so that the AI gets better and better at seeing the world in a complete, comprehensive, human (but actually superhuman) way. The clustering of various parts of an image or video together is called panoptic segmentation. Let’s explore this type of data annotation closer since it is a great way to train AI models.
What is Panoptic Segmentation and Why is It so Useful?
Panoptic segmentation is the process of segmenting image content with pixel-level accuracy. With panoptic segmentation, the image can be accurately parsed for both semantic contents (which pixels represent cars vs. pedestrians vs. drivable space), as well as for instance content (which pixels represent the same car vs. different car objects).
Planning and control modules can use panoptic segmentation results from the perception system to better inform autonomous driving decisions. For example, the detailed object shape and silhouette information help improve object tracking, resulting in a more accurate input for both steering and acceleration. It can also be used in conjunction with dense (pixel-level) distance-to-object estimation methods to help enable high-resolution 3D depth estimation of a scene.
So, how is all of this useful? Well, let’s imagine a complex scenario that a car might encounter, such as construction along the road. This means that there could be cones around the construction zone, maybe some debris that fell onto the road, and many other factors. If the car relies on bounding boxes to detect the object, it may have a hard time detecting the objects that do not neatly fit into a box. This is why panoptic segmentation is so useful because it provides a deeper and richer understanding of complex scenes.

What is It Important to Properly Annotate Your Training Data?
One of the reasons why Tesla is among the top companies developing autonomous vehicles is because their cars are equipped with sensors that collect a lot of real-world data from a fleet that now includes over a million vehicles. The automaker is able to use the extensive data set to improve its neural nets powering its suite of Autopilot features, and it ultimately believes it will lead to full self-driving capability.
However, that data is a lot more valuable when it is “labeled” – meaning that the information in the images collected by the fleet is being tagged with information, such as vehicles, lanes, street signs, etc. If the images are properly labeled – for example, if you can consistently recognize a speed sign and label it as such – you can feed a bunch of different images of different speed signs to a computer vision neural net in order to be able to recognize them. Labeling has been a focus of Tesla’s Autopilot team.
The latest project with panoptic segmentation will allow them to take the self-driving capabilities of Teslas to the next level and, perhaps, finally achieve the elusive Level 4 and maybe even Level 5 automation that we have all been waiting for.
Mindy Support Can Help You With All of Your Data Annotation Needs
Mindy Support knows first-hand the amount of data annotation required to train the machine learning algorithms inside autonomous vehicles. This is why we would like to take the burden of annotating such a large volume of data off your shoulders by setting offshore data annotation teams. We are the largest data annotation company in Eastern Europe with more than 2,000 employees in eight locations all over Ukraine and in other geographies globally. Contact us today to learn more about how we can help you.





