The Role of Artificial Intelligence in Automated Driving
One of the most interesting sessions at this year’s GTC conferences concentrated on the role artificial intelligence plays in autonomous driving. In this session, Volkswagen’s Lead SDS Software Engineer, Silviu Homoceanu, presented some very interesting information about some of the technologies used by researchers to allow the car to “see” the road and “learn” about all of the various conditions it might encounter while driving. In this article, we will take a look at some of the highlights of the presentations so we can gain a better understanding of the way AI powers the development of autonomous vehicles.

How Does the Car “See” the Road?
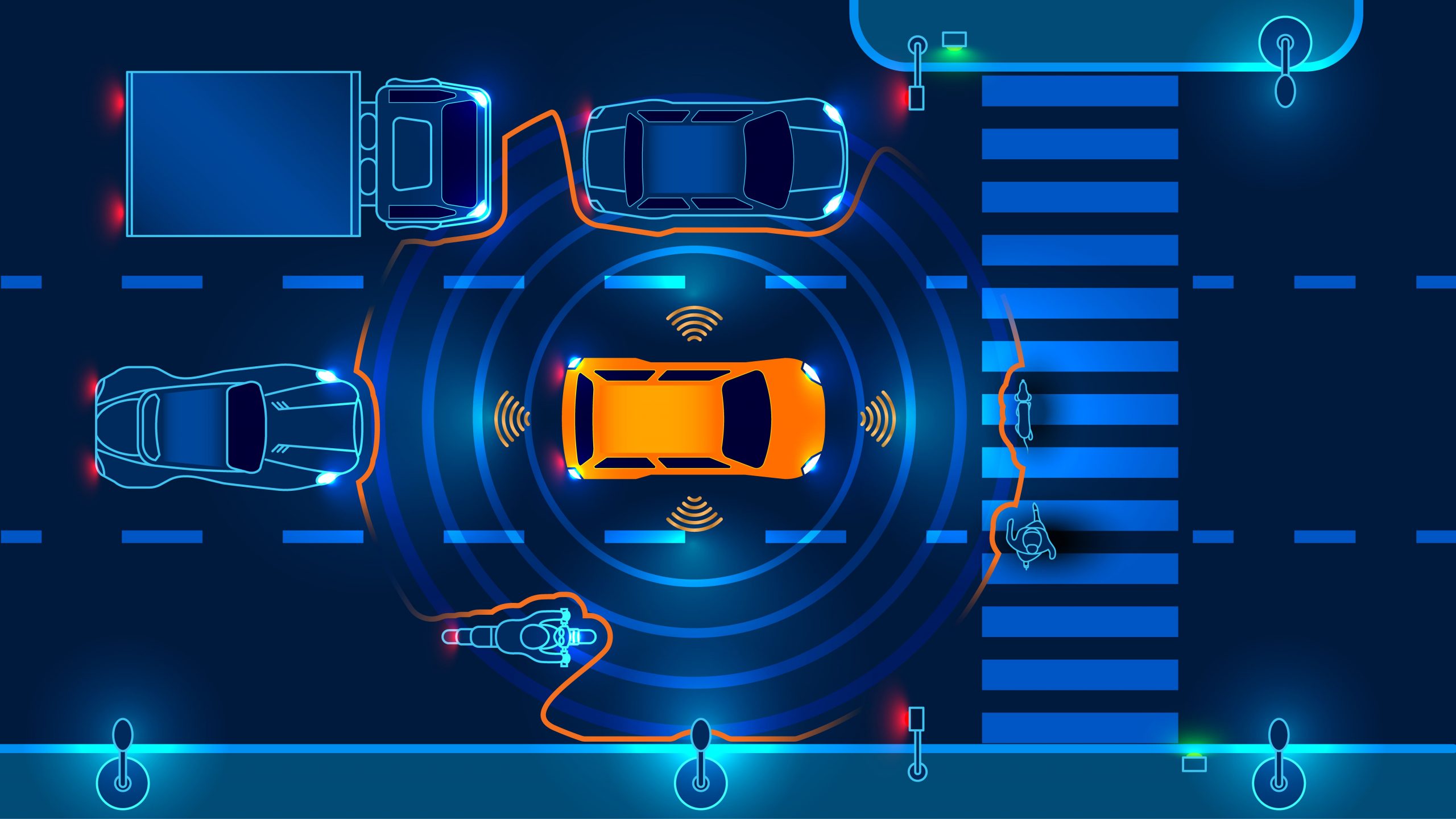
One of the technologies used to allow the car to “see” the road is LiDAR. First of all, there is 360-degree LiDAR, which allows the car to monitor every direction, all the time. There are also long-range LiDAR sensors that allow the car to track items that are more than 200 meters away. The way this technology works is it sends out a beam of light that bounces off another object and returns back to the LiDAR sensor. All of this produces a 3D Point Cloud which is a visual representation of the way the autonomous vehicle “sees” the physical world. In addition to LiDAR, there are also ultrasonic sensors that work in a similar fashion to LiDAR, except that they use sound waves instead of light to measure distances. Finally, there is a system of cameras mounted to the vehicles that capture data as well.
All of these technologies can be found in vehicles like the Volkswagen Sedric which is a prototype of a self-driving car presented by the Volkswagen Group way back in 2017 as their first-ever Level 5 autonomous car. There are other companies, like Waymo, who rely almost entirely on LiDAR. They have even developed their own LiDAR system, called Laser Bear Honeycomb which provides more coverage with fewer sensors, more customizable configurations, and other benefits. Finally, what conversation about autonomous vehicles can be complete without discussing Tesla and their Autopilot AI which relies on an intricate system of cameras, called the Hydranet, to stitch together all of the images into one view.
It is also important to note that all of these technologies simply produce raw data which later on needs to be prepared by humans with various data annotation methods. This ranges from simple labeling and bounding box annotation to more advanced annotation methods such as semantic segmentation and 3D Point Cloud annotation. You can find more information about this by visiting the data annotation section of our website.
How Does All This Work?
We listed all of the technologies that allow the car to “see” the road, but what does this like in practice? So all of the data was recorded, then it was annotated and used to train the convolutional neural network variables to steering angles until convergence and then deploy for inference in the car. Thanks to advances in frameworks like Tensorflow and hardware for inference like the NVIDIA Drive IX it has become a lot easier to conduct such experiments. One of the most interesting observations from Volkswagen’s researchers and was discussed in the presentation was that the convergence of a model was only a loose indicator for the ability of that model to drive independently. Only a small subset of the models that converged was able to drive longer without human intervention.
In order to test the models, they created a small course of simulations. They took all of the steering angles that were produced by the neural networks and apply a homographic transformation to the images in the next timestamp. This way the decision of the network would affect the input at every timestamp. So, what does all of this mean in plain English? Basically, whenever an image is recorded, the neural networks propose a steering angle based on this image that would keep the car from off the road. In this particular experiment, they recorded 3 minutes of data or 3,500 frames and in each of those frames, the machine learning system would need to correctly adjust the steering angle.
However, this brings up another question of what actually did the system learn from all of this data? It learned that there is a correlation between street markings and steering angle. So, for example, in order to stay in a particular driving lane, the steering angle needs to be adjusted accordingly.
How Can the Training Process Be Enhanced With Data Annotation?
The experiment described above did not go very well, so researchers decided to enhance the training process with the help of additional data annotation among other things. They took their training data and applied a method called Novelty Detection and Training Set De-biasing with the help of variational autoencoders. This method was used on both real and simulated data and to bridge the gap between the real and simulated data they trained the model on purposefully built semantic segmentation networks. The segmented data would be put into the model and the dataset was balanced in such a way that no novelties were detected.
If you are not familiar with the concept of novelty detection, this is when the machine learning system encounters an unknown object. One of the purposes of data annotation is to reduce the detection of such novelties as much s possible, but what we have learned from the experiment conducted by Volkswagen was that annotating the data set with semantic segmentation, which is one of the most advanced methods, helped eliminate the issue of novelty detection.
What Are Some Challenges That Need to Be Overcome?
While have been many new and interesting developments in the field of autonomous vehicles, there are still many challenges that need to be overcome:
- Training data – There needs to be a shift in the way the software is currently created to capture the right data. There are also obstacles in terms of annotating the data as well.
- Novelty and Corner Cases – Regardless of how well we try, there will always be situations where the vehicle will not know how to respond. We call such situations corner cases. This is in addition to the novelty detection issue we described earlier.
- Forgetting – Just like humans forget old information when learning something new, the machine learning models perform the same way. This is known as catastrophic forgetting.
- Uncertainty – A lot of times the neural network will not be 100% sure about identifying a particular object or making a decision. There may be even situations where 99% certainty is not good enough. Such uncertainty estimation still needs to be explored especially in semantic segmentation.
- Efficiency – We need to remember that all of the driving decisions need to be done in a fraction of a second, which puts a lot of pressure on the embedded hardware.
- Validating the results – When all of the research and testing has been done, the vehicle needs to get on the road to validate the results.
Mindy Support Can Help Take the Burden of Data Annotation Off Your Shoulders
As we have learned, data annotation is an important aspect of machine learning, but it is very time-consuming. This is why a lot of companies choose to outsource such work to a service provider. Mindy Support provides comprehensive data annotation services. We are one of the largest BPO providers in Eastern Europe with more than 2,000 employees in six locations all over Ukraine. Our size and location allow us to source and recruit the needed number of candidates quickly and we will be able to scale your project without sacrificing the quality of the data annotation. Contact us today to learn more about how we can help you.





