The Evolution of YOLO: Object Detection Algorithms
The evolution of object detection algorithms has been marked by rapid advancements, none more influential than the YOLO (You Only Look Once) series. Initially introduced in 2016, YOLO revolutionized the field by offering real-time object detection with remarkable speed and accuracy. This article traces the development of YOLO from its inception to its latest iterations, exploring how each version has pushed the boundaries of what’s possible in computer vision. From YOLOv1’s groundbreaking approach to the sophisticated architectures of YOLOv8, we delve into the innovations that have made YOLO a cornerstone in the world of deep learning and object detection.
What is YOLO?

YOLO, which stands for ”You Only Look Once,” is a cutting-edge object detection algorithm designed for real-time applications. Unlike traditional methods that process images in multiple stages, YOLO treats object detection as a single regression problem, predicting bounding boxes and class probabilities directly from full images in one evaluation. This approach significantly enhances speed and efficiency, allowing YOLO to process images at impressive frame rates while maintaining high accuracy. YOLO’s architecture is built on convolutional neural networks (CNNs), and it has evolved through various versions, each improving upon the last in terms of performance, precision, and adaptability to different environments and challenges in computer vision.
YOLO Object Detection: From Basics to Advanced
YOLO object detection has redefined how machines interpret visual data, offering a powerful and efficient solution for identifying and classifying objects within images. At its core, YOLO simplifies the object detection process by framing it as a single regression problem. Instead of processing an image multiple times to identify objects, YOLO divides the image into a grid and predicts bounding boxes, class probabilities, and confidence scores for each grid cell in one pass. This streamlined approach allows YOLO to achieve real-time detection speeds, making it ideal for applications requiring rapid and accurate object recognition, such as autonomous driving, surveillance, and robotics.
As YOLO has evolved, it has incorporated increasingly sophisticated techniques to enhance both its speed and accuracy. Early versions like YOLOv1 focused on basic grid-based prediction, but subsequent iterations introduced innovations such as anchor boxes, improved feature extraction networks, and multi-scale detection, significantly improving performance. The later versions, such as YOLOv4 and YOLOv5, have optimized the architecture further, integrating advanced concepts like cross-stage partial networks (CSPNet) and path aggregation networks (PANet) to balance speed with high precision. These advancements have made the YOLO model a versatile tool, capable of handling a wide range of real-world challenges in object detection, from detecting small objects in cluttered scenes to maintaining performance across diverse datasets.
Key Features of the YOLO Model
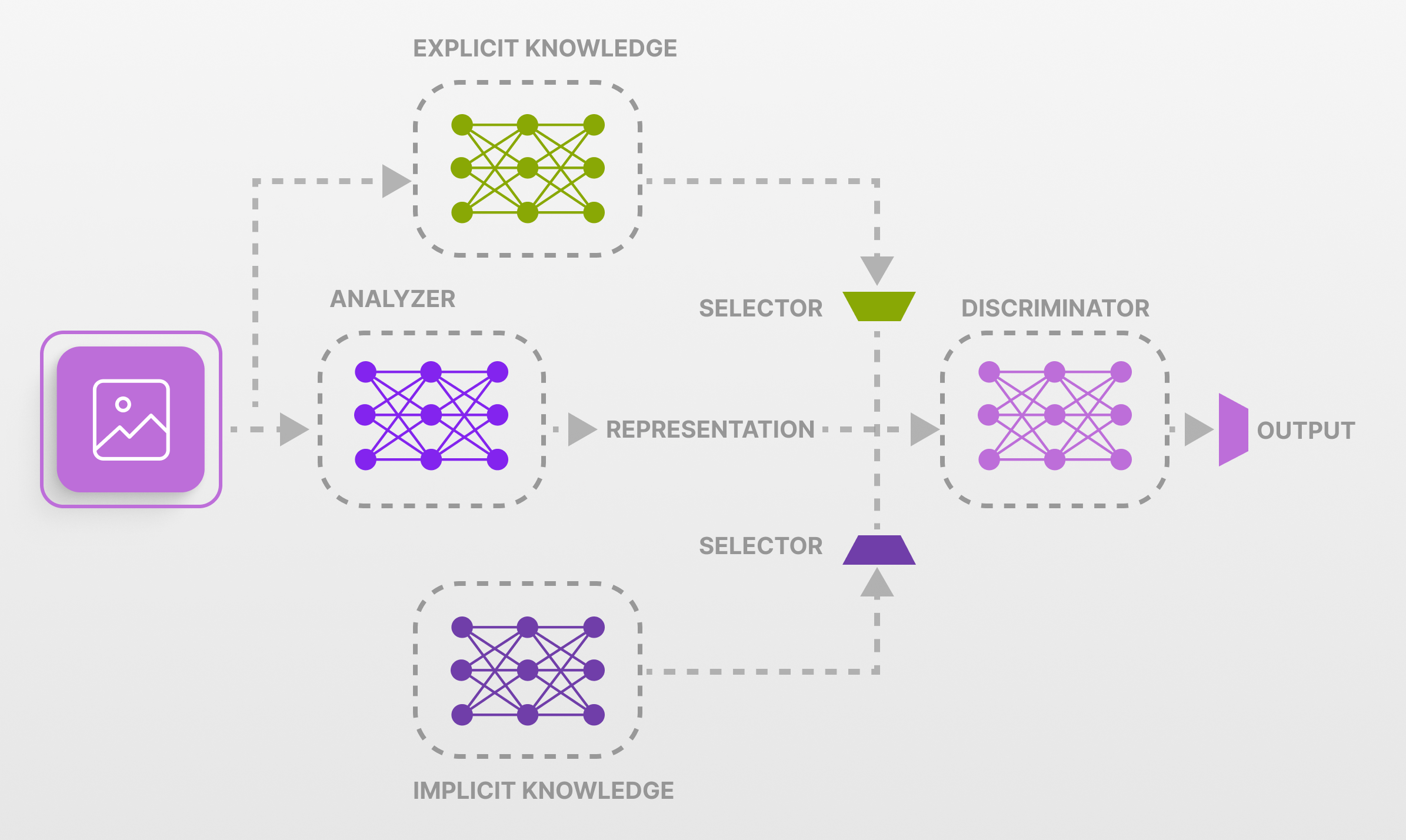
When it comes to YOLO, there are five key features that are important to know about:
- Real-Time Processing– YOLO is designed for real-time object detection, processing images at high frame rates without compromising accuracy. This makes it ideal for applications where speed is critical, such as autonomous vehicles and live video analysis.
- Single-Pass Detection – Unlike traditional object detection algorithms that require multiple passes over an image, YOLO models treat object detection as a single regression problem. It predicts bounding boxes and class probabilities in one evaluation, significantly reducing computation time.
- Grid-Based Prediction– YOLO divides an image into a grid and assigns each grid cell the task of predicting objects within its bounds. This approach simplifies the detection process and allows for the simultaneous detection of multiple objects in various locations within the image.
- Unified Architecture – The YOLO architecture is based on a single convolutional neural network (CNN) that handles both feature extraction and object detection. This unified approach contrasts with models that separate these tasks into different networks, resulting in a more efficient and streamlined process.
- High Accuracy and Versatility – YOLO has been optimized through successive versions to improve accuracy and handle a wide range of object sizes and types. Advanced features like anchor boxes, multi-scale detection, and improved loss functions help YOLO maintain high precision across diverse and complex datasets.
The YOLO Algorithm: Core Components and Functionality
The YOLO algorithm consists of several core components and functionalities that contribute to its high-speed and accurate object detection capabilities:
- Convolutional Neural Network (CNN) Backbone – YOLO uses a CNN to extract features from input images. The backbone network, such as Darknet-53 in YOLOv3, processes the image through multiple layers, capturing hierarchical features that are crucial for detecting objects at different scales.
- Grid-Based Prediction – YOLO divides the input image into a grid of cells. Each cell is responsible for predicting bounding boxes and their associated class probabilities for objects that fall within its boundaries. This grid-based approach enables YOLO to detect multiple objects in various locations within the image.
- Bounding Boxes and Anchor Boxes – YOLO predicts bounding boxes around objects along with confidence scores that indicate the likelihood of the box containing an object. In later versions, YOLO introduced anchor boxes, predefined box shapes that help improve detection accuracy, especially for objects of varying sizes.
- Single-Pass Detection– Unlike traditional methods that require multiple stages of processing, YOLO detection works in a single pass through the network. This involves predicting bounding boxes and class probabilities directly from the entire image, making YOLO exceptionally fast.
- Non-Maximum Suppression (NMS) – To refine detection results, YOLO uses Non-Maximum Suppression, a technique that filters out overlapping boxes by keeping the one with the highest confidence score. This ensures that each detected object is represented by a single bounding box.
How the YOLO Algorithm Works
We already looked at what’s YOLO so now we should take a look at how the YOLO algorithm works. It converts the object detection problem into a single regression task, enabling it to predict multiple bounding boxes and class probabilities in one pass through the network. It begins by dividing the input image into a grid of cells, where each cell is responsible for detecting objects that fall within its boundaries. Each grid cell predicts a fixed number of bounding boxes, along with the confidence scores that represent the likelihood of an object being present and the accuracy of the box.
Also, each bounding box prediction includes class probabilities, indicating the type of object detected. YOLO’s architecture leverages a convolutional neural network (CNN) to extract features from the image, which are then used to make these predictions. To ensure accurate detection, YOLO employs techniques like anchor boxes for handling objects of different sizes and Non-Maximum Suppression (NMS) to eliminate redundant bounding boxes, retaining only the most confident predictions. This streamlined, end-to-end approach allows YOLO to perform object detection in real-time with impressive speed and accuracy.
YOLO Models: Evolution and Enhancements
The YOLO computer vision models have been marked by continuous enhancements, each version building on the strengths of its predecessor while introducing new innovations to improve performance. Starting with YOLOv1, which revolutionized object detection by treating it as a single regression problem, subsequent versions have introduced significant improvements in speed, accuracy, and versatility. In the next couple of sections we take a closer look at the progression of YOLO versions starting with YOLOv1 and all the way to YOLOv8.
YOLOv1 to YOLOv5: Progressive Developments
The journey from YOLOv1 to YOLOv5 reflects a series of progressive developments that have significantly advanced the capabilities of object detection. YOLOv1, introduced in 2016, laid the foundation with its novel approach of treating object detection as a single regression problem, enabling real-time detection by predicting bounding boxes and class probabilities in one pass. YOLOv2, or YOLO9000, improved on this by introducing anchor boxes, batch normalization, and a more efficient network architecture, making it more accurate and capable of detecting smaller objects.
YOLOv3 further enhanced the model with Darknet-53, a deeper and more robust feature extraction network, and multi-scale predictions, allowing it to detect objects of varying sizes with greater precision. YOLOv4 introduced several optimizations, including Cross-Stage Partial (CSP) connections and a modified spatial pyramid pooling layer, which increased both accuracy and speed while reducing computational complexity. Finally, YOLOv5, though not developed by the original authors, brought significant practical improvements, including ease of use, training flexibility, and support for different hardware platforms, making it widely adopted in industry and research. These developments from YOLOv1 to YOLOv5 highlight a continuous refinement of the model’s speed, accuracy, and versatility in handling diverse object detection challenges.
YOLOv6 and Beyond: The Latest Innovations
YOLOv6 and the subsequent versions represent the cutting edge of object detection, pushing the boundaries of what is possible in terms of speed, accuracy, and efficiency. YOLOv6 introduced significant architectural enhancements, focusing on optimizing the model for deployment in real-world scenarios, particularly in edge computing environments. This version incorporated advanced techniques such as a refined backbone network, efficient convolutional layers, and innovative post-processing methods that reduce inference time while maintaining high detection precision.
Moving beyond YOLOv6, the latest iterations, like YOLOv7 and YOLOv8, have continued this trend by integrating state-of-the-art innovations like attention mechanisms and transformer-based components, which further enhance the model’s ability to detect complex and overlapping objects. These versions also emphasize scalability and flexibility, allowing for easier adaptation across different platforms and use cases, from mobile devices to high-performance servers. The evolution from YOLOv6 onward highlights a commitment to not only improving core performance metrics but also making the models more accessible and practical for diverse applications in the rapidly evolving field of computer vision.
Conclusion
When we look at all of the progress that has been made with YOLO image classification and all of the versions that were introduced over the years, each one offered advancements that enhance speed, accuracy, and versatility, making YOLO a leading choice for real-time applications across various industries. The transition from basic grid-based predictions to sophisticated architectures incorporating anchor boxes, multi-scale detection, and attention mechanisms showcases the algorithm’s adaptability to complex challenges in computer vision. As the field continues to advance, the ongoing development of YOLO reflects a commitment to refining object detection capabilities, ensuring that these models remain relevant and effective in meeting the demands of an increasingly data-driven world.





