LLM Fine-Tuning Powered by Industry Experts (2025 Edition)

Large language model fine-tuning developed from specialized technical expertise into an essential element for successful artificial intelligence creation by 2025. The process of adjusting powerful models to fit specific organizational needs has become mandatory for developers, research teams and businesses in all industries. This publication examines using LLM as a service plus streamlined operational protocols and forthcoming best practices that determine modern effective large language models 2025 customization.
Since Mindy Support has extensive expertise in fine-tuning large language models, including multilingual and domain-specific fine-tuning services, we prepared some strategies, workflows, and best practices you can start implementing in LLM projects today.
What is Fine Tuning LLM?

The basic procedure on how to fine tune large language models consists of applying additional training to a pre-trained model that demonstrates general language comprehension capability using specific text data for particular tasks. The method allows developers to modify an extensive foundation model for particular needs before building completely new training from the ground up. Training LLM on custom data modifies the existing model parameters to enhance performance on particular job functions which include legal document summarization, medical data analysis, code generation, and customer service chatbot optimization.
The objective behind fine-tuning large language models is to boost their competencies in both particular content sectors and designated textual material. A healthcare company using GPT-4 could improve its clinical understanding by adjusting its parameters for better medical terminology responses and financial organizations could use the same model to develop more compliant financial statements. A typical use of fine-tuning LLMs involves creating sentiment analysis models for specialized domains in addition to developing technical documentation systems and creating multilingual models for minor languages. The refinement process in fine-tuning makes certain that LLM products produce outputs that maintain linguistic coherence alongside relevant contextual content appropriate for specific applications.
Mindy Support brings extensive expertise in delivering high-quality data annotation services that are critical for effective LLM fine-tuning. With a deep understanding of diverse industry requirements and a commitment to precision, Mindy Support ensures that the training data is accurately labeled, contextually relevant, and ready to unlock the full potential of customized AI models.
Types of Fine-Tuning Approaches

There are several types of fine-tuning approaches, each tailored to different needs and resource constraints. Some of the most common ones include:
- Domain-Specific Fine-Tuning – A model becomes domain-specific when practitioners apply fine-tuning processes that optimize performance for specialized areas including medical contexts and legal practices as well as financial business sectors. The model achieves proficiency in generating professional content with few-shot learning and by undergoing training using specific industry terminology and data which makes it suitable for tasks like medical diagnostics and legal analysis and financial reporting.
- Multilingual LLM – Significant adjustments to language models aiming at their proficiency in processing and creating content across multiple languages are known as multilingual LLM fine-tuning. Supervised fine-tuning should be done in 50 or more languages which improves its capacity to process different linguistic elements thus making it suitable for worldwide applications that need multilingual understanding.
- LLM Training Services – Customers can use LLM as a service through supervised fine-tuning and reinforcement learning with human feedback (RLHF) to enhance models by using both structured information and human instructional input. The process of integrating custom data and content moderation ensures that the model meets specific requirements while maintaining ethical and safety standards..
- LLM Tool – The optimization of domain-specific LLM tools by specialists produces better OCR (Optical Character Recognition) alongside parameter-efficient transfer learning for NLP and deep text analysis functions to handle complex situations including document digitization among others. The customized models prove extremely practical for industries that need exact language processing solutions along with multilingual support including e-commerce operations and customer service departments together with content development platforms.
LLM Lifecycle
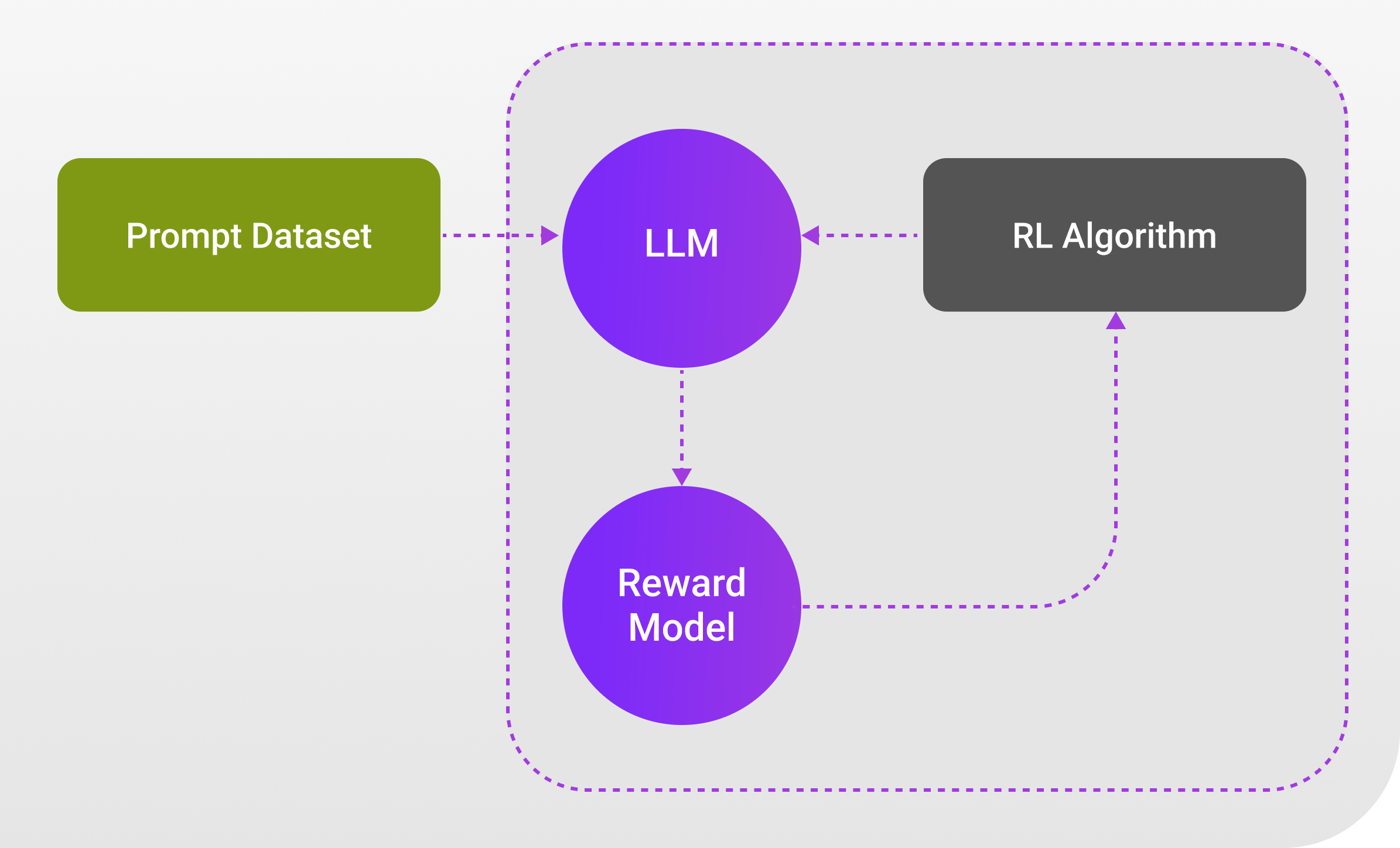
The large language model development lifecycle includes all development phases starting with mass data pre-training for training large language models before specialized fine-tuning and deployment to real-world applications. The model’s accuracy together with user needs and industry standards depends on regular evaluations and model retraining with updates along the complete lifecycle.
The development of an LLM project starts with a process that defines the project scope together with its future vision. The first step of this process requires establishing defined goals alongside user requirements and distinctive tasks that the language model will perform either in general use or dedicated applications such as healthcare or finance. The selection of the appropriate base model follows the scope definition and utilizes size, architecture, and pre-trained capabilities for the choice. Model selection stands as a critical decision that funds every subsequent process while determining how well the model matches the required task.
Performance assessment, LLM deployment, and evaluation become the main areas of attention following the completion of model selection. The model is optimized with specific data before undertaking performance evaluation through various metrics which include accuracy levels together with precision rates and Key Performance Indicators that match the domain. Evaluation occurs continuously while regular checks monitor the model’s developmental progress to prevent it from becoming too specialized for training information. Quality checks on the model and its parameters and data lead to the implementation of required modifications. The deployment phase starts following the model’s achievement of desired performance by integrating the model into real-world applications. Model performance monitoring after deployment takes place alongside efforts to plan needed model updates that stem from user feedback and changing needs.
Step-by-Step Guide to Fine-Tuning an LLM Tutorial
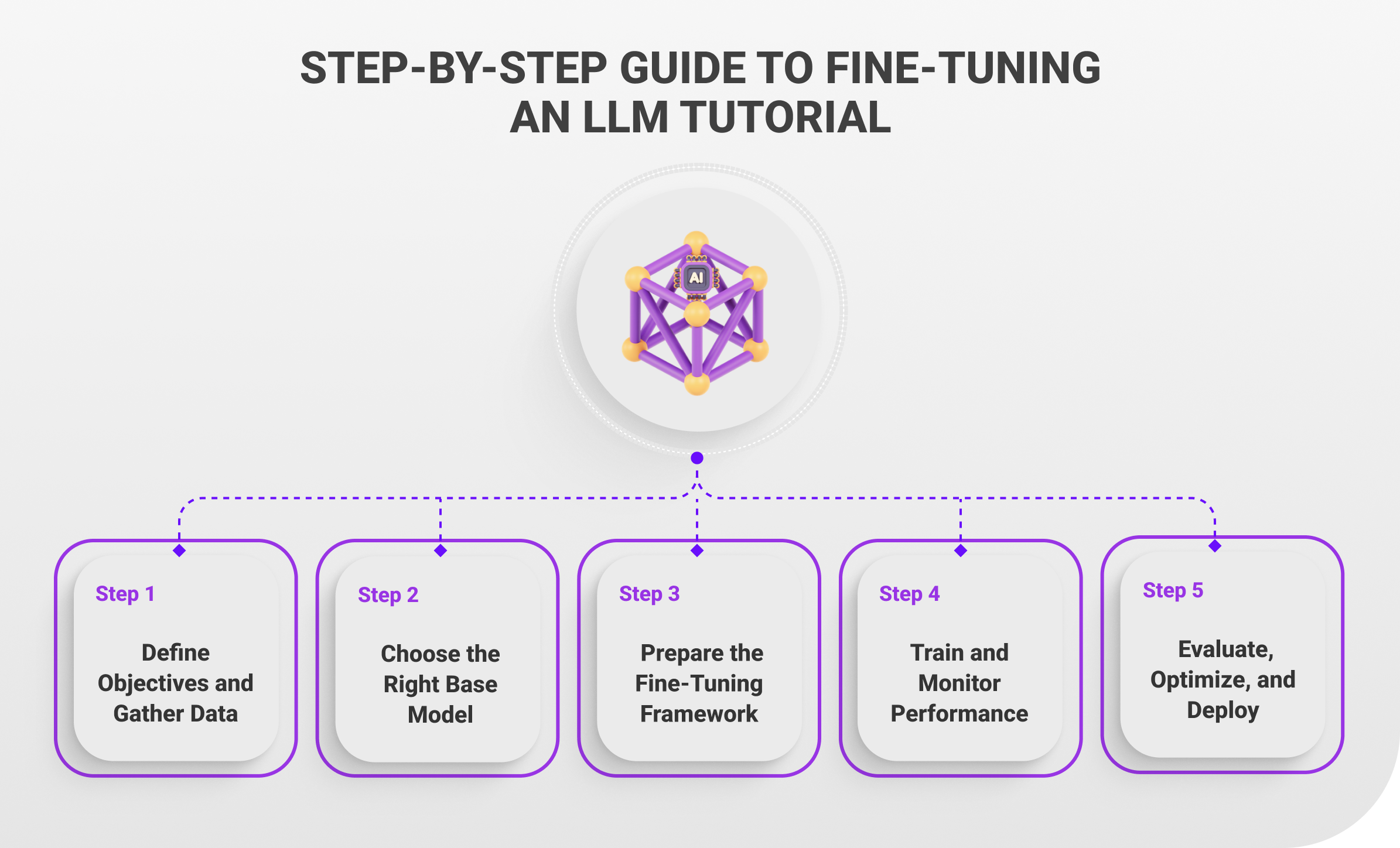
The process of how to fine tune LLM is specific for particular needs and tasks remains fundamental during its implementation. The guideline offers sequential instructions that lead users through necessary processes including data selection and model optimization for achieving optimal real-world performance.
- Step 1: Define Objectives and Gather Data – Begin by specifying the exact task along with its domain for your model specialization. The first step begins with defining your objective then you should collect high-quality representative data for the process. The quality together with the diversity and relevance of your data determine the success of meaningful fine-tuning outcomes.
- Step 2: Choose the Right Base Model – Identify a pre-trained LLM that offers suitable size and architectural specifications together with operational capabilities such hugging face model or others. Evaluate licensing conditions while checking computational needs together with domain suitability for your intended applications.
- Step 3: Prepare the Fine-Tuning Framework – Determine your technical framework from available options which include Hugging Face Transformers, TensorFlow, and PyTorch for your project. Your deployment will require full fine-tuning or parameter-efficient approaches (LoRA or adaptors) or prompt-based methods which depend on how much funding and purposes you have.
- Step 4: Train and Monitor Performance – You should apply the model to your specialized dataset for a more targeted training process. The model learning process should be monitored through key metrics including loss and accuracy and domain-specific evaluation criteria to verify appropriate model development. Early stopping serves as an essential approach to stop overfitting in the training process.
- Step 5: Evaluate, Optimize, and Deploy – Execute thorough performance evaluations of your model through unseen data testing which facilitates the assessment of its generalization abilities. After model optimization includes hyperparameter adjustment or model simplification you should deploy the fine-tuned model for production use or application integration.
Best Practices for Effective Fine-Tuning

To get the most out of training large language models, following a set of best practices is essential. These LLM fine tuning best practices help ensure the process is efficient, and scalable, and results in a model that performs reliably in real-world scenarios.
- Data Quality and Quantity – High-quality, well-labeled data is the foundation of effective fine-tuning. It’s essential to use a dataset that is both relevant to your task and large enough to provide the model with sufficient examples to learn from, without introducing noise or bias.
- Hyperparameter Tuning – Fine-tuning success often hinges on carefully adjusting hyperparameters such as learning rate, batch size, and number of epochs. Even small changes can significantly impact model performance, so experimentation and validation are key.
- Regular Evaluation – Consistently evaluating your model on validation and test sets ensures that it is learning effectively and generalizing well. Regular evaluation helps catch overfitting early and guides further tuning or data adjustments.
- Avoiding Pitfalls – Common fine-tuning pitfalls include overfitting, catastrophic forgetting, and using misaligned or low-quality data. Staying vigilant and following structured workflows can help avoid these issues and maintain model integrity throughout the process.
RAG vs Fine Tuning

The selection between fine-tuning and retrieval augmented generation (RAG) depends on matching project requirements. For applications that require specific domain models, you should consider fine-tuning because it updates pre-trained internal parameters with task-specific data. The process of fine-tuning consumes large computational power alongside the necessity for extensive high-quality data groups.
The Retrieval-Augmented Generation (RAG) method joins language models with retrieval systems which enables them to retrieve suitable external data during inference thereby improving its operational power in situations requiring updated information. The RAG method demonstrates superior performance in assignments that need constant updates or present-time information like question answering from recent news sources. The selection between RAG vs LLM and fine-tuning stand as a function of the available processing potential along with a combination of domain suitability requirements coupled with live knowledge needs and customization levels for particular operational needs.
Mastering Custom LLM Models: The Path to Optimal Performance
AI development requires experts to master LLM fine-tuning while determining the proper application of advanced tools like Retrieval-Augmented Generation (RAG) to keep their position in the field competitive. The application of proper LLM fine tuning methods between model refinement and external information usage will boost both models effectiveness along with their relevance. Your decision-making process when applying these factors enables better performance outcomes with enhanced impact. AI progress requires organizations to preserve adaptability and expertise in strong customization methods to fully utilize their language models’ potential.





