Can AI Enforce Facebook’s User Guidelines?
Facebook is one of the most popular social networks in the world with around 2.89 billion users. On average 350 million photos are uploaded daily to Facebook and there is 1,500 average number of posts that are eligible to appear in a Facebook user’s feed each day. As you can imagine, it’s not possible for human employees to review and approve such a massive volume of content that appears on Facebook every day. This is why Facebook is relying on AI to help them police the platform and remove content that violates its rules and regulations. However, how effective can AI be in taking on such challenges? How can it discern between and forbidden content? These are some of the questions we will explore today.

How Does Facebook’s AI Content Moderation Work?
Although Facebook is notoriously secretive about its AI policies, they did tell us how the AI content moderation system works:
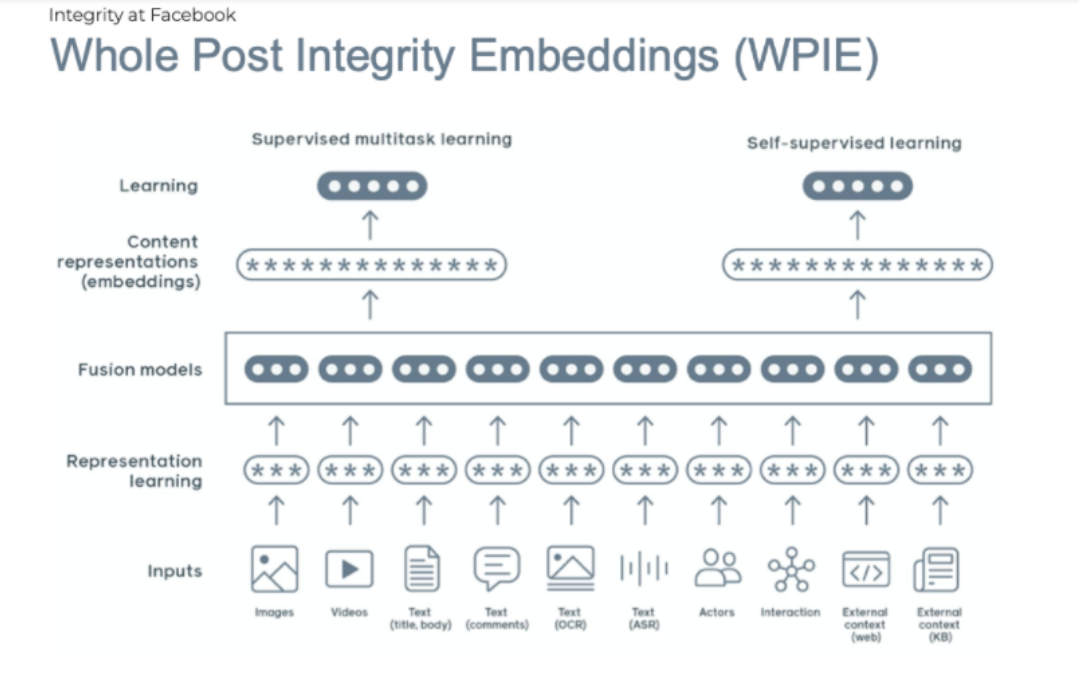
Image source: The Verge
Let’s explore what we see in the image in greater detail. After the user uploads some sort of content, regardless of the format, it then goes to representation learning. This is where the system extracts particular features or aspects that may violate the rules. For example, for written content, this can be something like profane language, racial and ethnic slurs, and many other things. The same would be true for images and videos, even though moderating visual content is a bit more challenging than written content. This information then goes to the fusion models where the data is indexed and stored for real-time discovery. Then we see the content representation stage, which is where the model is provided with a useful vantage point into the data’s key qualities, which also helps train the overall model.
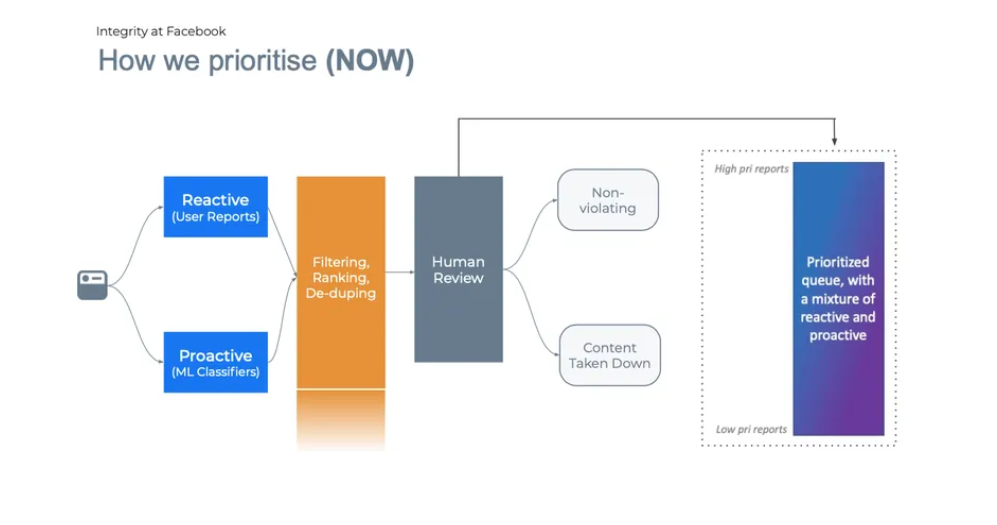
If the model spots something that violates the guidelines, it will send it over for human review as we can see in the picture below:
How is the AI System Trained to Identify Forbidden Content?
In the previous section, we talked about how certain features of the content are extracted by the machine learning algorithms to better understand the nature of the post, image, or video. However, how do they know what to look for? This is where data annotation comes into play. Basically, human data annotators need to prepare a training dataset for the machine learning algorithms to learn. For textual content, this can be things like the classification and categorization of certain phrases. For images, this is usually semantic segmentation, tagging, and 2D/3D bounding boxes. Annotating videos is similar to regular images, but you would need to annotate all of the frames.
For example, high-quality video will usually be shot in 60 frames per second (fps). This means that there are 60 frames that need to be annotated for every second of the video. Therefore, if you have a video that’s, for example, one minute long, you can imagine how much data annotation this would require. Having said this, Mindy Support will be able to annotate all of the data you need, regardless of the scope of the project.
How Effective Has Facebook’s AI Been in Moderating Content?
Facebook has recently released its Community Standards Enforcement Report where it says that the prevalence of hate speech in Q2 2021 declined for the third quarter in a row. This was attributed to improvements in proactively detecting hate speech and ranking changes in the Facebook News Feed. It is also worth painting out that Facebook removed 31.5 million pieces of hate speech content in Q2, compared to 25.2 million in Q1, and 9.8 million from Instagram, up from 6.3 million in Q1. While there is always room for improvement, these are certainly very impressive results.
Another interesting aspect is the advancements Facebook made in zero-shot and few-shot learning. This enables AI systems to recognize violating content, even if they’ve never seen it before or have only seen a few examples of it during training. The main goal of this method is to map the image features and semantic attributes into a common embedding space using a projection function, which is learned using deep networks. These are very advanced features and capabilities, so the achievements of Facebook’s engineers are certainly impressive.
What is the Conclusion?
Using AI to moderate content is definitely the best way to go because content can be reviewed and filtered automatically—faster and at scale. Inappropriate content can be flagged and prevented from being posted almost instantaneously. All of this can be used to support human moderators’ work in order to speed the process with greater accuracy. It also helps protect human moderators from seeing traumatic images. You can read more about the type of content Facebook moderators are exposed to and their harmful effects here.
Trust Mindy Support With All of Your Data Annotation Needs
Regardless of the volume of data, you need to be annotated or the complexity of your project, Mindy Support will be able to assemble a team for you to actualize your project and meet deadlines. We are the largest data annotation company in Eastern Europe with more than 2,000 employees in six locations all over Ukraine and in other geographies globally. Contact us today to learn more about how we can help you.





