Increasing Quality of a Training Dataset for Large German Automotive Tier 1

Сlient Profile
Industry: Automotive
Location: Germany
Size: 2000+
Company Bio
The company boasts a rich heritage of innovation and precision engineering, setting the benchmark for automotive excellence globally. Its dedication to cutting-edge technology and sustainable practices underscores its commitment to shaping the future of mobility.
Introduction
By leveraging state-of-the-art techniques and our expertise in data enhancement, Quality Match and Mindy Support worked with a leading German Tier 1 in the automotive industry to help them toincrease the quality of their data set for training their sensors for object detection for an ADAS level 3 system. The visual dataset for ML to train the AI system to recognize pedestrians on the road required rigorous quality assuranceto optimize the annotated data. This process was essential for identifying and rectifying errors, ensuring the integrity of future datasets.
Project Overview and Goal

In this project, the German Tier 1 provided multiple data sets annotated by one of their annotation partners. Mindy Support and Quality Match analyzed and compared the quality of annotations of the different datasets and flagged the annotation mistakes that needed correction. In this process the focus was on evaluating the annotations using three key quality assurance metrics;False Negatives (FN), False Positives (FP) and Geometric Accuracy. Additionally, the attribute occlusion was checked as it was one of the priorities of the customer.
The annotated datasets contained 2D Bounding Box annotations of pedestrians that needed to be checked, which resulted in the following questions to be answered to derive the quality metrics mentioned above.
- Is the person in the vehicle?
- Is the object a: depiction (poster, billboards, images, mannequin, statue), reflection, animal or other/ can’t solve?
- Is the person in the box fully visible?
- How many people can you see inside the box?
Project Execution
Mindy Support and Quality Match collaborated in this project using the expertise, knowledge and experienced related to annotated automotive data and optimizing quality of datasets. While Mindy Support executed countless data annotation projects inside and outside the autonomous driving industry, thus having extensive knowledge about all relevant data formats, annotation types, classes and attributes as well as quality metrics, Quality Match provided an innovative quality assurance tooling that allows to reduce complexity by asking simple questions about already annotated datasets in a special decision tree which enforces the inspection of all aspects of the annotation quality with statistical methods.
In a first step, Quality Match and Mindy Support deconstructed the complex quality assurance tasks into individual, one-dimensional decisions, so called “nano-tasks”. This approach reduces the burden on the reviewer, by focusing the view on single annotations and one aspect of the quality metrics.

Instead of asking the reviewer to process and check an entire image at once, each decision or attribute within the image is treated as a separate, isolated task. This minimizes the likelihood of overlooked errors or inaccuracies due to cognitive overload and helps identify ambiguity or edge cases more easily. The nano-tasks are then structured as a logical decision tree, starting with broad questions and narrowing down to specifics based on previous responses. This approach ensures that no unnecessary questions are asked, thus optimizing the time and resources spent on the task.
To benefitfrom a statistical analysis, the same nano-task can be answered by multiple reviewers, so-called “repeats”. Adding repeats for each quality assured annotation allows introducing statistical guarantees on the results, which is valuable for identifying ambiguity as well as enabling certifiably with actual evidence. This is particularly relevant for complying with upcoming data quality standards such as ISO-5259-2.
Furthermore, when multiple reviewers provide conflicting answers, the decision-tree methodology aids in identifying the root cause of such disagreements. For instance, if the object in question is blurry or dark, or if the question itself is unclear, the issue can be quickly identified and rectified, thereby enhancing the accuracy and efficiency of the overall quality assurance process. For this project, 5 iterations for each nano-task were used.
Results
Analyzing the datasets according to the different quality metrics for False Negative (FN) and False Positive (FP) Rates, Geometric Accuracy and Occlusion Level Accuracy showed the following main findings.
(1) One dataset contained 17% of False Negatives
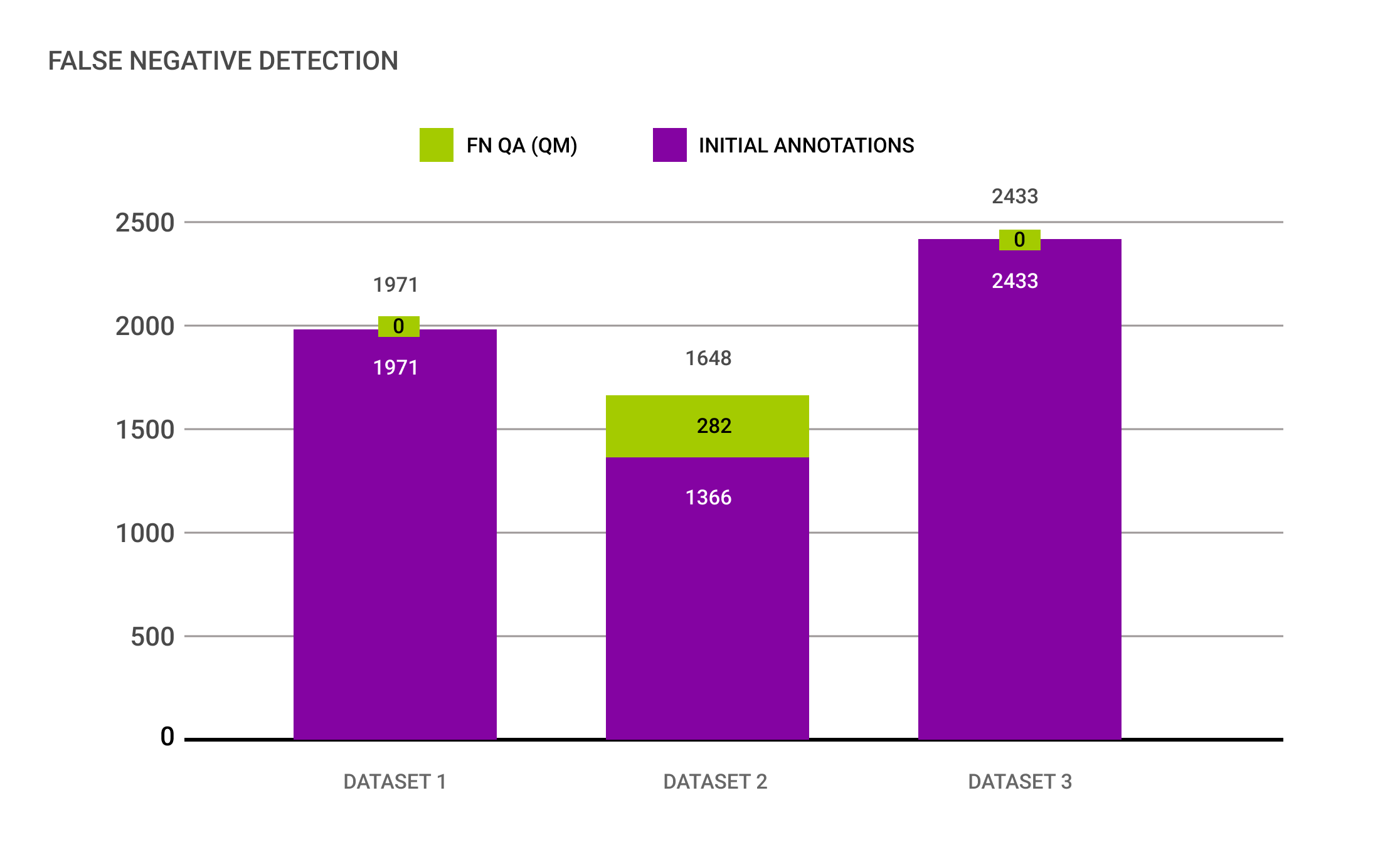
Since other datasets didn’t contain such a high rate, the results were shared back with the German Tier 1 to discuss potential improvements for future annotations of datasets, resulting in a fine-tuning of the taxonomy to make clear, which type of object has to be included in the annotation process.
(2) All datasets had few False Positives, with an average of 1% of FPs per dataset
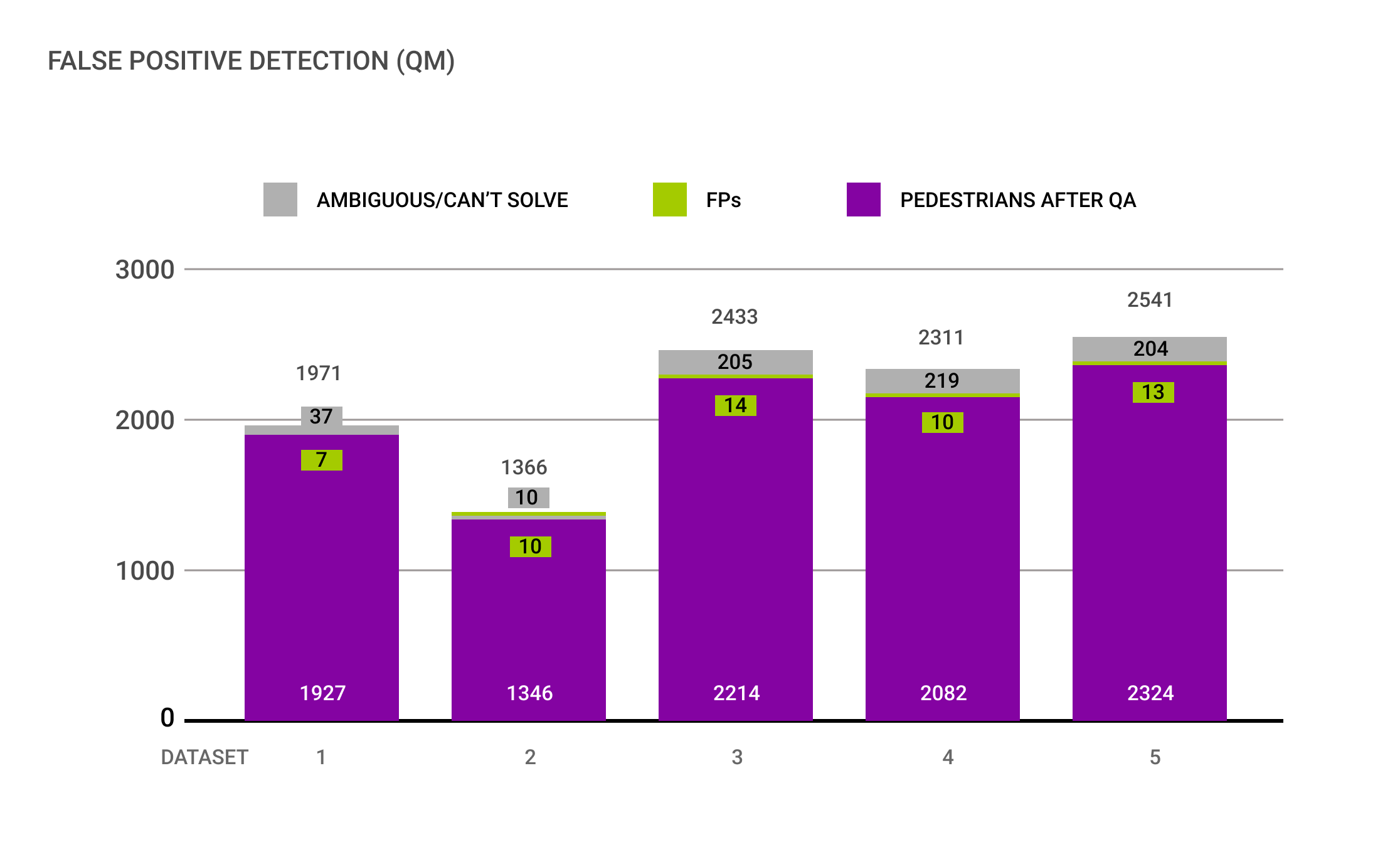
The majority of FPs presented were related to Riders labeled as Pedestrian, resulting in the suggestion to improve the taxonomy, which might help to differentiate between these classes.
Additionally, using the innovative repeats approach from Quality Match showed up to 10% of ambiguous annotations. Ambiguity can be caused by small or blurry annotations and are often disregarded in quality assurance processes. It is crucial though to understand if a training dataset is (too) ambiguous to be able to increase the ML model’s performance.
(3) 2-6% of the annotated 2D Bounding Boxes had a bad geometric accuracy
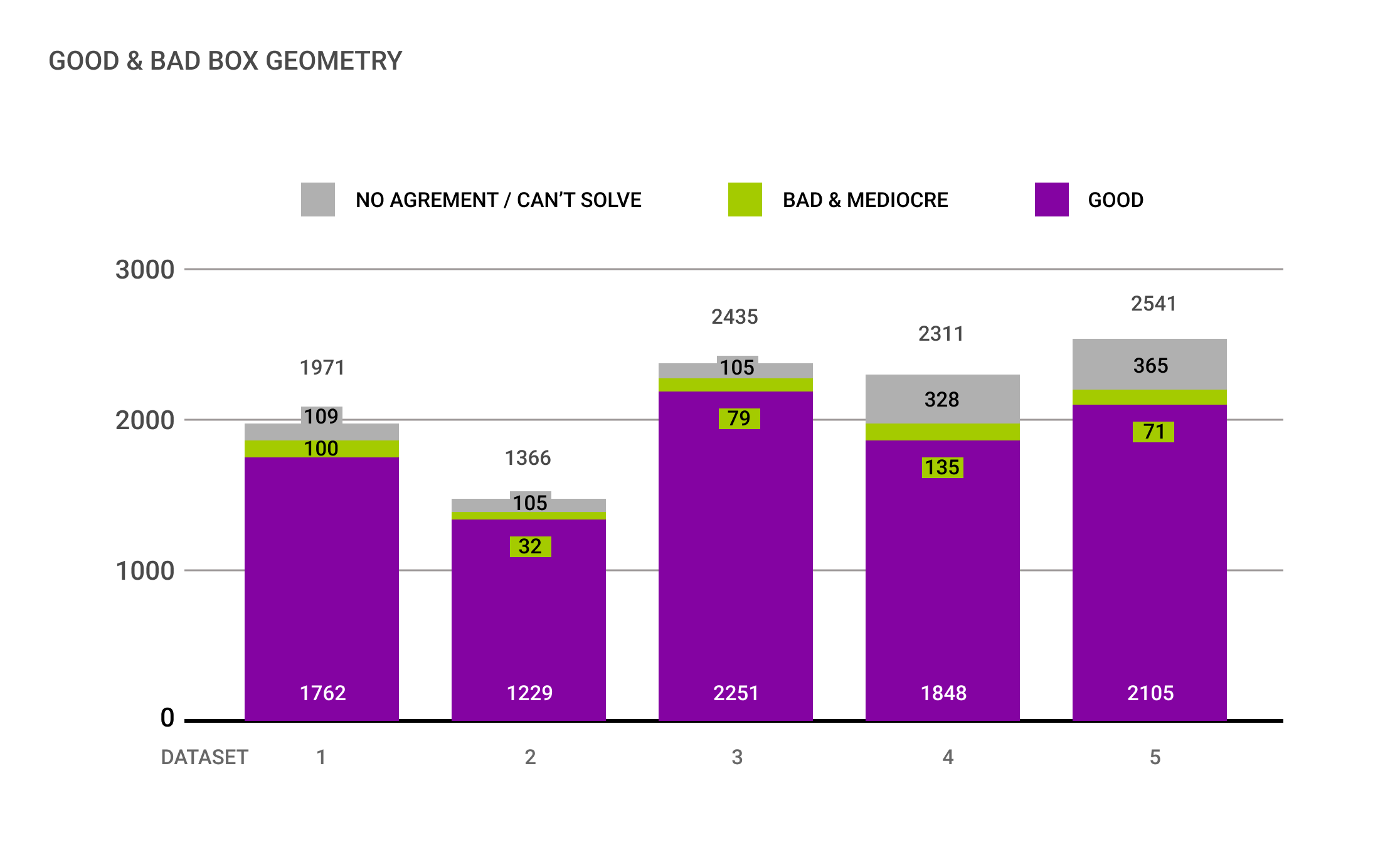
(4) Occlusion levels varied drastically across all datasets, with the highest differences of +200%
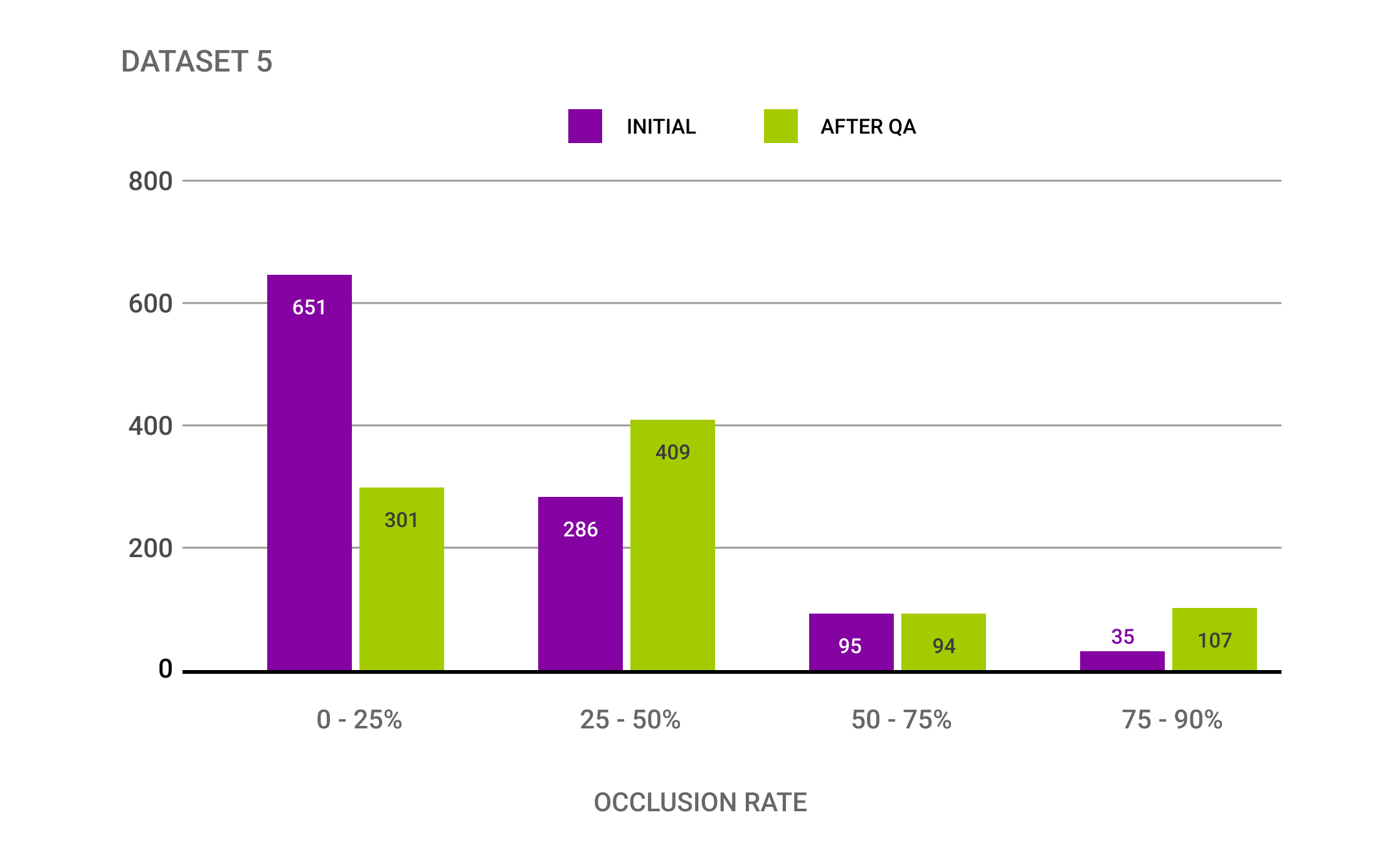
The graph aboveshows the significant differences between the initial occlusion levels and the occlusion levels after the QA nano-task from Quality Match and Mindy Support. The occlusion level of 75-90% shows an increase of 205% after the quality check was done. Further investigation showed that the original labeling taxonomy didn’t include sufficient examples of what different occlusion levels can look like, resulting in the high changes above.
Summary

The main major takeaway of the quality assurancedone by Mindy Support and Quality Match is that inconsistencies and insufficient examples in the label guide can result in different definitions of the same task during the annotation process. Recommendations for label guide homogenization and alignment were made to avoid such issues in the future. Furthermore, the innovative QA approach showed several overlooked errors while giving additional information such as ambiguity of annotations, both resulting in an enhanced understanding of the dataset’s quality, which directly impacts the quality of the to-be-trained ML mode. Our successful outcomes reflect the unique collaboration between Quality Match and Mindy Support, blending our respective expertise with innovative AI-driven tools. This partnership highlights the effectiveness of our combined approach in achieving exceptional results.
Errors Overview
- One dataset contained 17% of False Negatives
- All datasets had few False Positives, with an average of 1% of FPs per dataset
- 2-6% of the annotated 2D Bounding Boxes had a bad geometric accuracy
- Occlusion levels varied drastically across all datasets, with the highest differences of +200%
GET A QUOTE FOR YOUR PROJECT
We have a minimum threshold for starting any new project, which is 735 productive man-hours a month (equivalent to 5 graphic annotators working on the task monthly).



