Audio Annotation Services
Audio annotation plays an important role in the development of chatbots,
virtual assistants and other NLP technology. Mindy Support provides
comprehensive audio annotation services covering all of the various
annotation types listed below.

Types of Audio Annotation Services We Provide
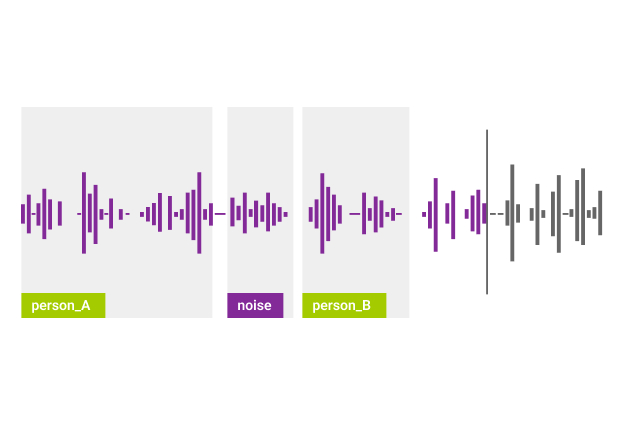
Sound Labeling
With sound labeling, the data annotators are given a recording and they need to separate all of the needed sounds and label them. For example, these can be certain keywords or the sound of a specific musical instrument.
Event Tracking
Event tracking evaluates performance of the sound event detection systems in multisource conditions similar to our everyday life, where the sound sources are rarely heard in isolation. In this task, there is no control over the number of overlapping sound events at each time, not in the training nor in the testing audio data.
Speech to Text Transcription
Speech to text transcription is an important part of creating NLP technology. It involves taking recorded speech and transcribing them to text while carefully labeling both words and sounds that the person pronounces. It is also important to use the right punctuation as well.
Audio Classification
Audio classification is listening and analyzing audio recordings. Using this data, the machines are able to differentiate between sounds and voice commands. This type of audio annotation is important in the development of virtual assistants, automatic speech recognition and text to speech systems. There are many different types of audio classification:
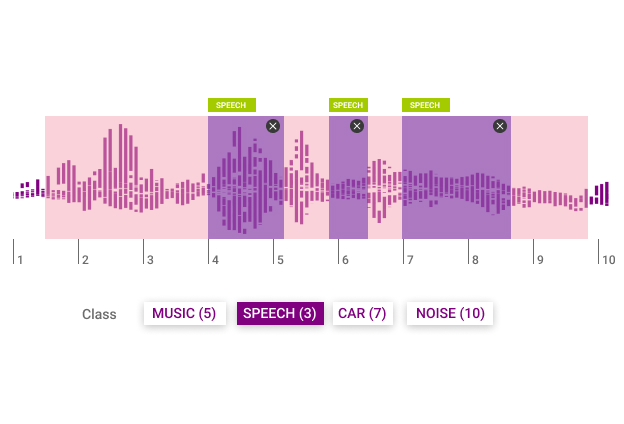
Types of Audio Classification
- Acoustic Data Classification
- Environmental Sound Classification
- Music Classification
- Natural Language Utterance Classification
- This form of data annotation involves identifying exactly where the sounds were recorded. The data annotators need to differentiate between all kinds of environments such as homes, schools, cafes and almost anything else. This is very useful for maintaining sound libraries for audio multimedia and in creating monitoring systems as well.
- Just like the name implies, the data annotators need to categorize various sounds that can be attributed to various environments. For example, there are certain sounds that are specific to cities such as construction, car horns, sirens and many other sounds. This is very useful for creating security systems that can identify sounds of break-ins and also for predictive maintenance as well.
- There are many things that could be classified here such as the genre, instruments played, ensemble type and many other things as well. This type of annotation is very useful for organizing music libraries and improving user recommendations.
- This type of annotation requires classifying small details such as dialect, semantics and many other things found in human speech. This is very important because this is what allows chatbots and virtual assistance to better understand human speech.
Acoustic Data Classification
Environmental Sound Classification
Music Classification
Natural Language Utterance Classification
- This form of data annotation involves identifying exactly where the sounds were recorded. The data annotators need to differentiate between all kinds of environments such as homes, schools, cafes and almost anything else. This is very useful for maintaining sound libraries for audio multimedia and in creating monitoring systems as well.
- Just like the name implies, the data annotators need to categorize various sounds that can be attributed to various environments. For example, there are certain sounds that are specific to cities such as construction, car horns, sirens and many other sounds. This is very useful for creating security systems that can identify sounds of break-ins and also for predictive maintenance as well.
- There are many things that could be classified here such as the genre, instruments played, ensemble type and many other things as well. This type of annotation is very useful for organizing music libraries and improving user recommendations.
- This type of annotation requires classifying small details such as dialect, semantics and many other things found in human speech. This is very important because this is what allows chatbots and virtual assistance to better understand human speech.
Acoustic Data Classification
Environmental Sound Classification
Music Classification
Natural Language Utterance Classification
Multi Label Audio Annotation Tasks
Multi label audio annotation is the process of placing multiple labels to identify overlapping sound sources in temporally-complex urban soundscapes. There are three main types of tasks:
Binary-labeling
Determine whether a single suggested sound-source class was present or not in the recording. This task type provided both positive and negative labels explicitly.
One-stage multi-labeling
The data annotators are presented with a list of class labels and they need to select all the sound-source classes present in the audio.
Two-stage hierarchical multi-labeling
In the first stage, the audio is presented to the data annotators alongside a list of superclass labels and they need to identify the sounds. At the second stage, this same audio is given to a different data annotator This task type provides positive labels explicitly and negative labels implicitly.
Our Clients


















Why Choose Us
-

2000+ people
-

GDPR compliance
-
ISO 27001:2013 certification
Download the certificate -
ISO 9001:2015 certification
Download the certificate




Let’s Expand with Mindy!
We have a minimum threshold for starting any new project, which is 735 productive man-hours a month (equivalent to 5 graphic annotators working on the task monthly).