Deepseek x LLMs: Get the 411
Large language models (LLMs) function as key agents of transformation in the field of artificial intelligence which continues moving forward swiftly. Advancements in AI have brought forward large language models which produce human-level text comprehension and generation to transform human technology interactions with applications in chatbots and search engines. The integration of LLMs with Deepseek marks one of their outstanding applications since the platform goes beyond current intelligent search capabilities. In this examination we identify what large language models represent and the specific practices Deepseek uses to unlock their full capabilities for information retrieval transformation.
What Are Large Language Models?
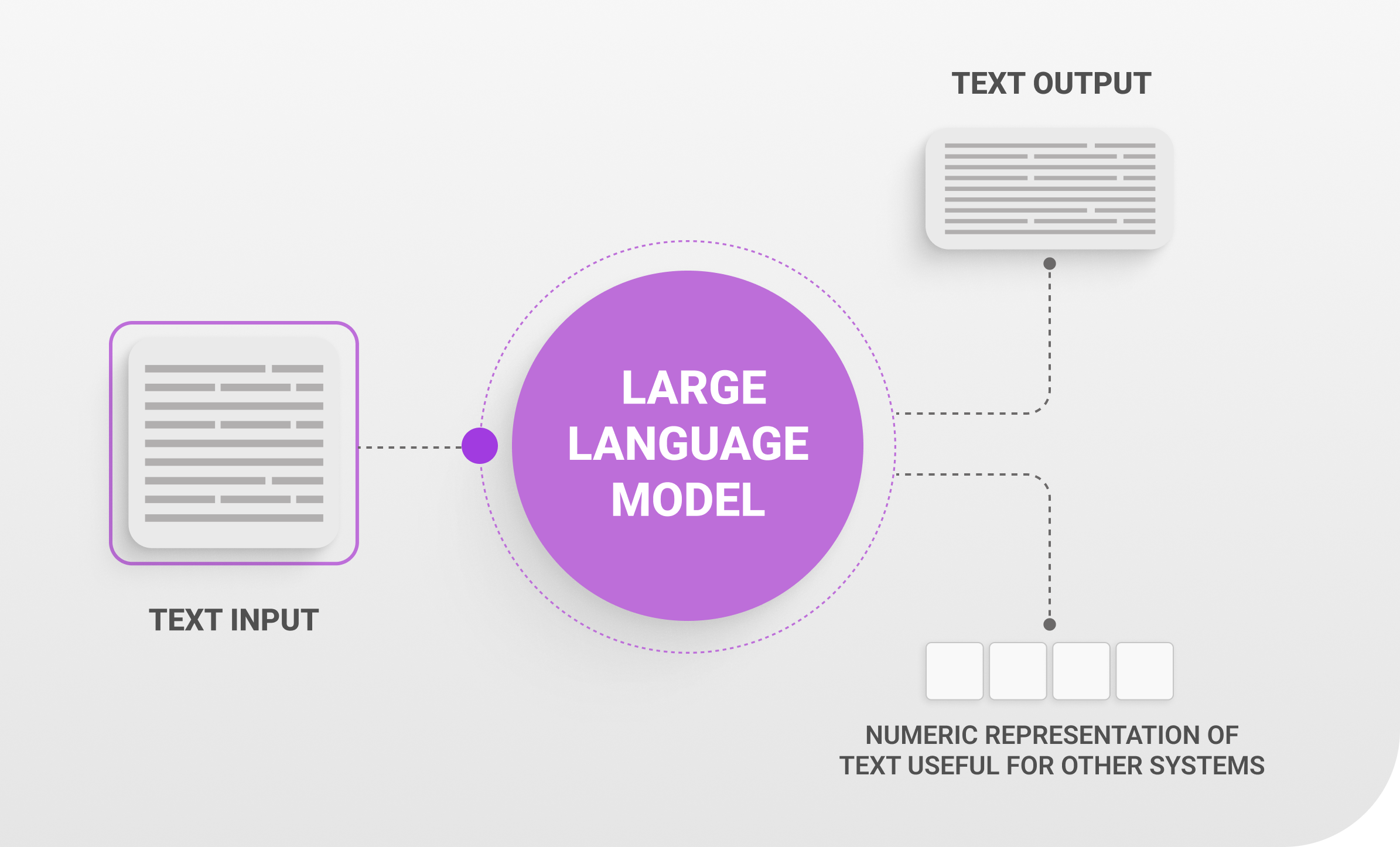
Large language models function as a class of artificial intelligence systems capable of interpreting and producing natural language content. Leveraging extensive training from books and articles on websites alongside numerous text sources these models learn sequential word prediction which allows them to generate code, write essays and answer questions.
The “large” in LLMs refers to their scale. Models like OpenAI’s GPT-4 and Google’s PaLM boast billions of parameters, making them capable of nuanced understanding and context awareness. These capabilities enable LLMs to excel in applications such as:
- Content Generation – Large Language Models (LLMs) process natural language inputs to produce diverse high-quality content including websites and creative works. Enterprises benefit from these tools when crafting social media messages alongside tailored customer communications and marketing material. With the help of Large Language Models (LLMs) content creators can develop story ideas while building scripts and generating relevant narratives for intended audiences.
- Language Translation – LLMs perform outstanding text translations between languages while maintaining accurate communication that preserves original context and meaning. These systems translate text faithfully by understanding idiomatic expressions together with cultural subtleties which creates the feeling of natural relatable text. LLMs offer businesses critical advantages through instantaneous multilingual services together with worldwide content localization capabilities.
- Sentiment Analysis – Using Large Language Models (LLMs) researchers can analyze text sentiment to classify emotions into positive categories or negative categories or neutral ones. By processing vast volumes of data they provide a means to comprehend customer feedback along with social media opinions and market trends. LLMs allow businesses to improve customer satisfaction while making data-based decisions from actionable insights which emerge from sentiment analysis patterns.
- Semantic Search – LLMs extend semantic search capabilities through their ability to understand user query intention together with context instead of finding direct keyword equivalents. These systems deliver reliable search outputs that properly address questions during complex or natural language-based conversations. Applications such as knowledge bases e-commerce platforms and enterprise search systems benefit from this capability because it improves overall user experience.
Despite their versatility, LLMs’ true potential depends on how they’re applied—and that’s where Deepseek comes in.
How Deepseek Maximizes the Potential of LLMs

Deepseek leverages LLMs to enhance search experiences, offering results that are more relevant, context-aware, and intuitive. Here’s how:
- Semantic Search for Precision – Traditional search methods which depend on matching exact keywords frequently offer results that don’t meet user needs when their search queries lack specific terminology. Semantic search via Deepseek’s LLM integration delivers results based on the user’s evaluation of intent alongside query meaning. The LLMs assess the search query to present options that meet users’ actual needs.
- Contextual Understanding – Language models demonstrate superior performance in understanding environmental context. The Deepseek system employs these tools to personalize search refinement by examining historical user interactions together with current preferences and conversation-specific details. The system creates results that change as users interact since their requirements continue to develop.
- Dynamic Summarization – Through the use of LLMs Deepseek can create brief summary versions of extended documents or articles. Users save time while they increase their productivity since they get essential information right away without having to read everything.
- Domain-Specific Optimization – Deepseek enhances industry models beyond general-purpose LLM capabilities to serve specialized sectors which include healthcare and legal processes or educational systems. Passing tailored models through Deepseek’s system brings users precise field-focused data information rather than broad, irrelevant answers.
- Natural Language Interaction – Deepseek transforms platform interactions into expert dialogues through seamless natural language conversational search features. Deepseek improves user interaction through its ability to comprehend detailed search questions which it answers using natural human-like dialogue to offer accessible search experiences.
The Challenges of Using LLMs
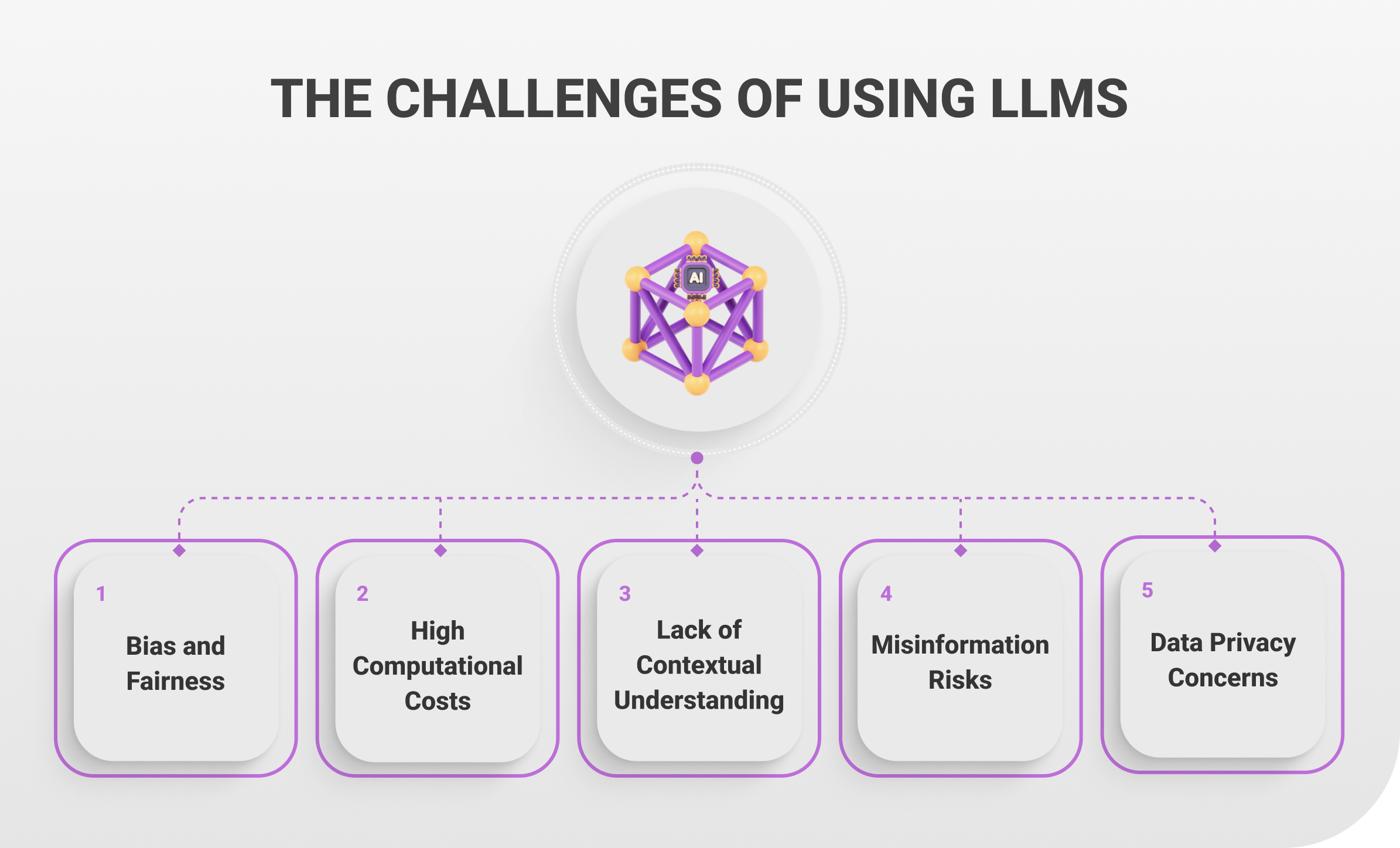
While Large Language Models (LLMs) offer transformative capabilities across industries, their implementation is not without significant challenges. These issues range from technical limitations to ethical concerns, requiring careful consideration to ensure their responsible and effective use. Below are five key challenges of using LLMs, with an expanded explanation of each.
- Bias and Fairness – Large datasets containing societal biases along with stereotypes and representation imbalances form the training ground for LLMs that collect data mostly from internet sources. These systems unintentionally generate outputs that repeat such biases while further intensifying them. Certain professions or social roles may become linked to specific genders and ethnicities through the processing of an LLM. Successful mitigation involves carefully chosen training data together with strict bias testing followed by the use of refining techniques which include fine-tuning and post-processing methods. The complex problem of creating completely fair solutions continues to evolve, which presents additional difficulties in multilingual and multicultural settings.
- High Computational Costs – Operating LLMs requires large-scale computational resources which frequent utilization of GPU and TPU hardware to train and deploy. These requirements escalate operational expenses along with creating serious environmental effects because they consume excessive energy. The extensive infrastructure requirements to scale these AI models prevent many small organizations from using advanced machine learning technologies while building barriers to access state-of-the-art AI. Progress exists in LLM optimization techniques such as model compression and distillation but resource demands keep presenting major obstacles.
- Lack of Contextual Understanding – Language models create texts which appropriately match context while remaining deficient in genuine world comprehension and human-like reasoning. Such limitations result in generator-produced texts which appear convincing yet fail logic tests because they contain incorrect facts and lack alignment with practical world contexts. In some cases LLMs deliver erroneous medical recommendations while misunderstanding legal questions because of incorrect reasoning. The limitations observed in LLM outputs demonstrate the necessity for precise validation and specialized customization according to each domain when used in critical application areas.
- Misinformation Risks – LLMs generate plausible yet wrong material which creates possible misinformation risks. It creates an urgent problem when LLMs become tools for writing news articles and academic texts alongside other trusted materials. The lack of thorough monitoring makes it possible for these systems to accidentally distribute incorrect content which undermines trust and results in societal harm. To prevent these issues organizations need verification systems for content and must educate users together with safeguards that show users how AI-generated content creation happens.
- Data Privacy Concerns – The use of sensitive or proprietary data in training or during user interactions with LLMs raises significant privacy concerns. For example, if an LLM is exposed to private information, there is a risk it could inadvertently reproduce that data in its outputs. This is particularly problematic in industries like healthcare, finance, or law, where confidentiality is paramount. To address this, organizations must adopt robust data handling practices, ensure compliance with privacy regulations, and explore privacy-preserving techniques such as differential privacy and federated learning.
Conclusion
Large language models are reshaping the AI landscape, and platforms like Deepseek are maximizing their potential to revolutionize information retrieval. By leveraging semantic search, contextual understanding, and domain-specific optimization, Deepseek offers an unparalleled search experience. As LLMs continue to evolve, innovations like Deepseek will undoubtedly lead the charge in making AI more accessible, accurate, and impactful.





