AI Training Data for Better Model Performance
High-quality, human-verified training data for LLMs, ML models, & enterprise AI systems.
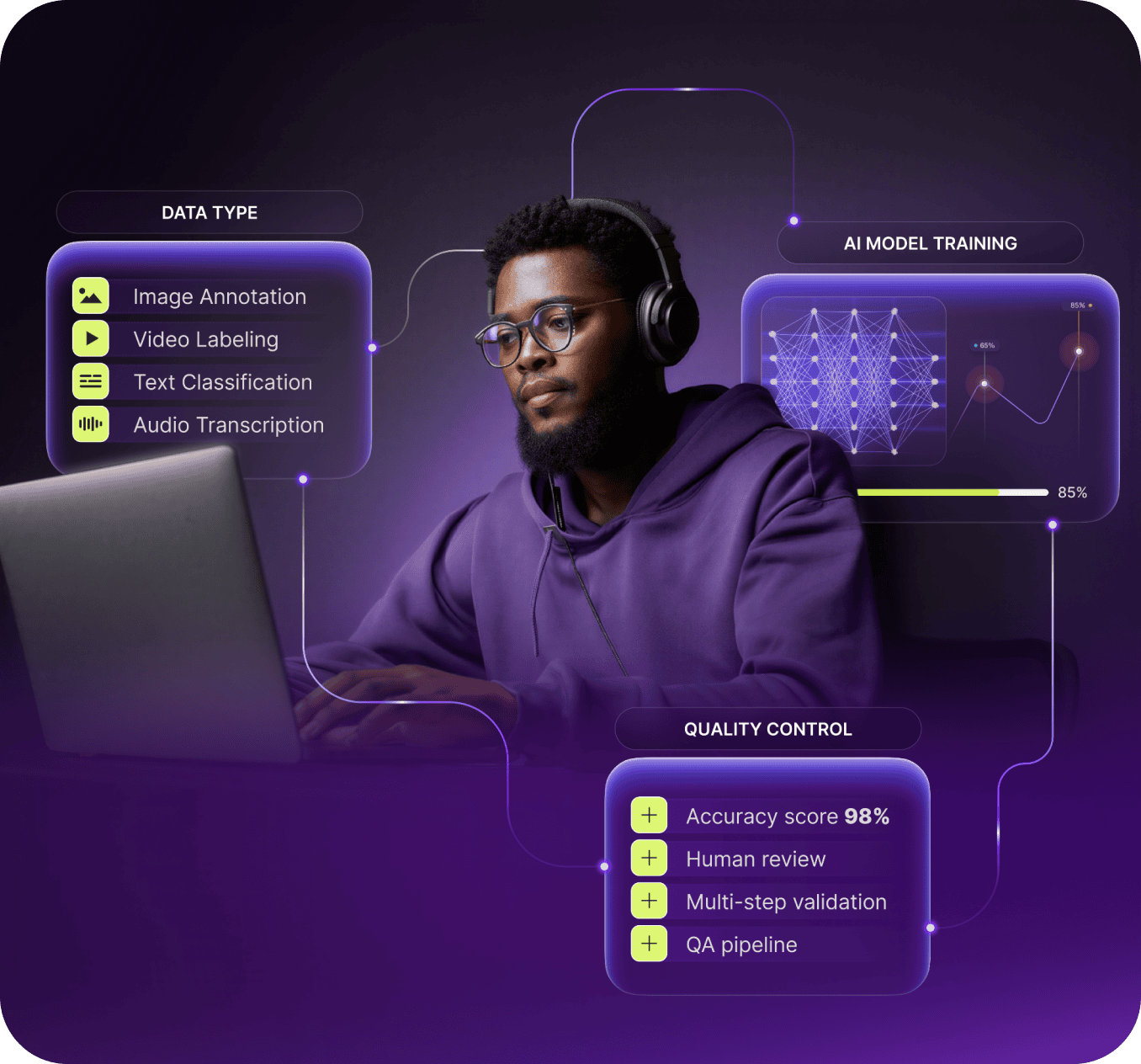
What Is AI Training Data?
AI data training is the process of collecting, labeling, validating, and refining datasets used to train machine learning and generative AI models. High-quality training data is critical for model accuracy, safety, and real-world performance.

End-to-End Training Data Services
Computer Vision
?>Image & video annotation
We provide high-quality image and video annotation services to power computer vision and AI models.
Object detection & segmentation
We deliver accurate object detection and segmentation to help AI systems understand and interpret visual data.
3D mapping & spatial labeling
We provide precise 3D mapping and spatial labeling to help AI systems understand depth, distance, and real-world environments.
Medical & industrial vision datasets
We create high-precision medical and industrial vision datasets tailored for complex, real-world applications.

Natural Language Processing & LLMs
?>Text annotation & classification
High-quality text labeling and classification to train AI models for sentiment analysis, topic detection, and language understanding.
Named entity recognition & intent labeling
Accurate tagging of entities, intents, and relationships to help AI systems better understand context, meaning, and user intent.
Conversation datasets & prompt engineering
Creation and annotation of conversational datasets and prompts to improve chatbot, assistant, and LLM interaction quality.
Multilingual language datasets
Scalable multilingual data collection and annotation to support AI models across global languages and markets.

Autonomous Systems & Mobility AI
?>ADAS & autonomous driving annotation
Precise annotation of road scenes, vehicles, pedestrians, and traffic elements to train autonomous driving and ADAS systems.
Sensor fusion (video, LiDAR, radar)
Integrated annotation of multi-sensor data including video, LiDAR, and radar to improve perception accuracy in autonomous systems.
Scene understanding & behavior tagging
Detailed labeling of road scenarios and agent behaviors to help AI models interpret complex real-world environments.
Safety validation datasets
High-quality datasets designed to test, validate, and improve the safety and reliability of autonomous systems.

Generative AI & Foundation Models
?>Training data curation for GenAI
Careful sourcing, filtering, and structuring of datasets used to train generative AI and large foundation models.
RLHF & human feedback annotation
Human-in-the-loop annotation and evaluation to align AI outputs with human expectations and improve model performance.
Content evaluation & ranking
Systematic review and ranking of AI-generated content to refine output quality and relevance.
Bias and hallucination checks
Specialized annotation workflows to detect bias, misinformation, and hallucinations in AI-generated responses.

Speech & Audio AI
?>Audio transcription & labeling
Accurate transcription and labeling of speech data to train and improve voice-based AI systems.
Speech recognition datasets
Large-scale datasets prepared for training and evaluating automatic speech recognition models.
Speaker identification
Annotation of voice characteristics to enable AI systems to recognize and differentiate between speakers.
Multilingual voice datasets
Collection and labeling of diverse multilingual voice data to support global speech AI applications.

Domain-Specific AI
?>Healthcare & Medical Imaging
Specialized annotation of medical images and healthcare data to support AI applications in diagnostics and clinical research.
Retail & E-commerce AI
Data preparation and annotation for AI models used in product recognition, recommendation systems, and retail analytics.
Technology Platforms & Big Tech AI
Scalable data operations designed to support AI development for large technology platforms and digital ecosystems.
Industrial & Robotics AI
High-precision datasets for robotics, automation, and industrial computer vision systems.



Human-in-the-Loop AI Data Training

Expert Annotators
Domain-trained teams combining human expertise

Multi-Stage QA
Built-in quality validation at every step

Scalable Delivery
Rapid ramp-up for enterprise workloads

Secure Operations
GDPR-compliant data environments
Data Types
Images, video, text, and audio – we transform raw data into structured, high-quality datasets that teach AI systems to understand and interact with the world.







Enterprise-Grade Quality & Compliance
Quality and trust are at the core of everything we do. Our enterprise-grade processes ensure your data meets the highest standards of accuracy, security, and compliance.

ISO-aligned QA processes

GDPR & data privacy compliance

Secure and trusted environments

Ethical & responsible AI practices
Why Leading AI Teams Choose Mindy Support

Our AI Data Training Process:

Our clients



AI Training Data FAQs
What is AI training data ?
AI training data is the process of preparing, labeling, and structuring datasets so machine learning models can learn to recognize patterns, understand language, and make accurate predictions.
How do you ensure data quality?
We ensure high data quality through multi-layer quality assurance, expert annotators, standardized workflows, and continuous validation to deliver accurate and reliable AI training datasets.
Can you provide multilingual training data?
Yes. Mindy Support provides multilingual data annotation and collection services across multiple languages to support global AI and machine learning models.
Do you support LLM and generative AI training?
Yes. We support LLM and generative AI training with services such as text annotation, prompt and response evaluation, content moderation, and dataset preparation.
