Datensammlung
für maschinelles Lernen
Rohdaten sind ein wesentlicher Bestandteil eines jeden Machine Learning Projekts.
Wie aber kommen Sie an Rohdaten? Machen Sie es sich einfach und lassen Sie Mindy Support
die erforderlichen Trainingsdaten sammeln.


Wieso sollten Sie bei Trainingsdaten auf Qualität achten?
In der Machine Learning Community gibt es ein beliebtes Sprichwort: „Garbage in, Garbage out“. Wenn Sie bei der Modellentwicklung qualitativ minderwertige Trainingsdaten verwenden, können Fehlentscheidungen die Folge sein. Besonders in Branchen, in denen Fehlentscheidungen schwerwiegende Konsequenzen haben können, wie der Automobilindustrie oder dem Gesundheitswesen, muss ein besonderes Augenmerk auf die Qualität der Trainingsdaten gelegt werden.

Mindy Support als Partner bei der Datensammlung
Durch langjährige Data Annotation Erfahrung verfügt Mindy Support über tiefgreifendes Fachwissen darüber, wie Trainingsdaten für die verschiedensten Projekte aussehen, strukturiert werden müssen und welche Hürden bei der Beschaffung von Trainingsdaten auftreten. Während wir unter Ihrer Anleitung Daten sammeln, können Sie sicher sein, dass Sie sich in guten Händen befinden, Sie die Daten bereit zur Annotation bekommen und sich währenddessen voll und ganz auf die Entwicklung Ihres Produktes konzentrieren.
Typen häufig gesammelter Trainingsdaten

Einen Datensatz zu finden, der genau die Bilder enthält, die Sie für Ihr ML/KI-Projekt benötigen, kann ein zeitaufwändiges Unterfangen sein. Anstatt das Internet selbst zu durchforsten oder für einen vorgefertigten Datensatz zu zahlen, der mehr schlecht als recht für das Modell geeignet ist, können wir einen passgenauen Datensatz für Sie erstellen. Unsere Date-Collection Dienstleistungen umfassen ein breites Spektrum verschiedener Bilder für alle Formen von Machine Learning und Deep Learning Anwendungen. Sagen Sie uns einfach, wonach Sie in den Bildern suchen und was das Modell lernen soll, und wir kümmern uns darum.


Wir wissen nur zu gut, wie viele Audiodaten zum Trainieren eines NLP Modells, eines Voice-to-Text Modells oder andere ML-Modelle erforderlich sind, die menschliche Sprache verstehen können. Die Aufnahmen müssen ganz bestimmte Nuancen enthalten, die in echten Dialogen vorkommen, wie Ironie, Sarkasmus und viele andere Details. Wir können Trainingsdaten mit den nötigen Lexika sammeln, sowohl allgemein als auch domänenspezifisch (z. B. Namen, Orte, natürliche Zahlen). Die Audiodaten können zusätzlich als Textkorpora transkribiert und mit morphologischen Informationen und benannten Entitäten annotiert werden.


Heutzutage wird Maschinen beigebracht, Texte zu lesen, zu verstehen, zu analysieren und auf eine für die technologische Interaktion mit Menschen wertvolle Weise zu produzieren. Bevor Machine Learning Modelle natürliche Sprache verstehen können, müssen sie mit ausreichenden Mengen an qualitativ hochwertigen Textdaten trainiert werden. Bei der Sammlung von Textdaten können wir alle Arten von Stimmungen (positiv, negativ, neutral) oder Absichten, die dahinter stehen, wie Befehl, Frage oder Bestätigung, berücksichtigen.


Da es sich bei biometrischen Daten um personenbezogene Daten handelt, die aus einer bestimmten technischen Verarbeitung resultieren und sich auf die physischen, physiologischen oder verhaltensbezogenen Merkmale einer natürlichen Person beziehen, ist die Zustimmung zur Erhebung und Verarbeitung notwendig. Außer, Sie haben bereits einen, müssen biometrische Datensätze fast immer neu generiert werden. Wir können Ihnen dabei helfen, erforderliche biometrische Trainingsdaten unter Einhaltung aller Gesetze und Vorschriften zu sammeln, beispielsweise Gesichtsbilder oder personenbezogene Geostandorte.


Wenn Sie einen Trainingsdatensatz benötigen, der nicht aufgeführt ist, können wir auf Anfrage die benötigten Daten für Sie sammeln. Es gibt sehr verschiedene Arten von Machine Learning Unterfangen, manche mit sehr speziellen Anforderungen an benötigte Daten. Mit über 2000 Mitarbeitern und jahrelanger Erfahrung in Datensammlung und Annotation unterstützen wir Sie gerne bei der Zusammenstellung Ihrer Trainingsdaten, im Rahmen dessen, was technisch und rechtlich möglich ist.

Fallbeispiele für Datensammlung



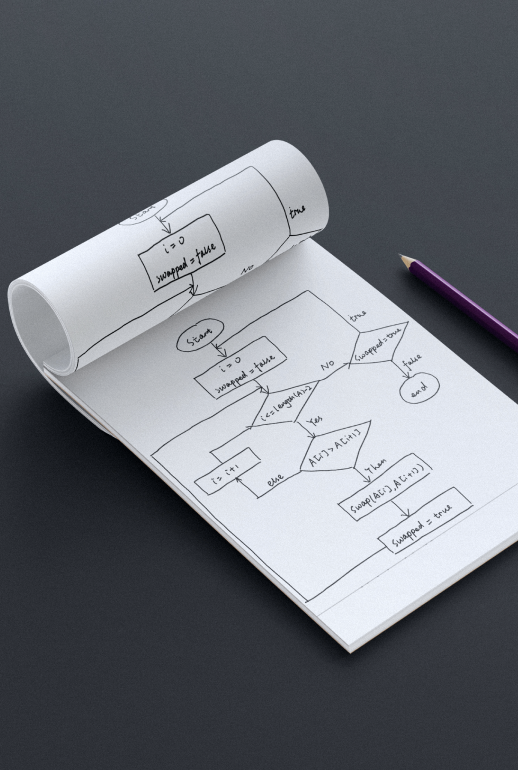




Datensammlung und Datenannotierung
Durch Annotation werden Rohdaten zu Trainingsdaten, anhand derer Maschinen lernen können. Ohne Annotation können KI/ML Modelle die Daten nicht verstehen. Mindy Support kann die für Sie gesammelten Daten auf Wunsch auch annotieren. Wir sind in der Lage, Bilddateien, Videodateien und Text mit allen gängigen Methoden zu annotieren, sodass Sie Ihre Trainingsdaten sofort verwenden können.
Arbeiten Sie mit führenden Spezialisten an Ihrem KI/ ML-Projekt
Unser kleinster Projektumfang liegt bei 735 produktiven Arbeitsstunden pro Monat. Das entspricht 5 Data Annotation Spezialisten, die jeden Monat an einem Projekt arbeiten.