Audio Annotation
Audio Annotation spielt eine wichtige Rolle bei der Entwicklung von Chatbots,
Sprachassistenten und anderen NLP-Technologien.
Unsere Kompetenzen umfassen das Labeling von Audio Dateien und Transkription,
um deren Inhalt zu beschreiben, maschinenlesbar zu machen und NLP-Systeme zu trainieren.
Die Audiodaten stammen üblicherweise von Menschen, Instrumenten, Tieren, der Umwelt oder selteneren Quellen.

Audio Annotation Dienstleistungen
Klang Beschriftung
Sound Labeling bedeutet bestimmte Geräusche aus einer Audioaufnahme zu identifizieren, zu trennen und zu kennzeichnen. Dabei kann es sich beispielsweise um bestimmte Schlüsselwörter oder den Klang eines bestimmten Musikinstruments handeln.
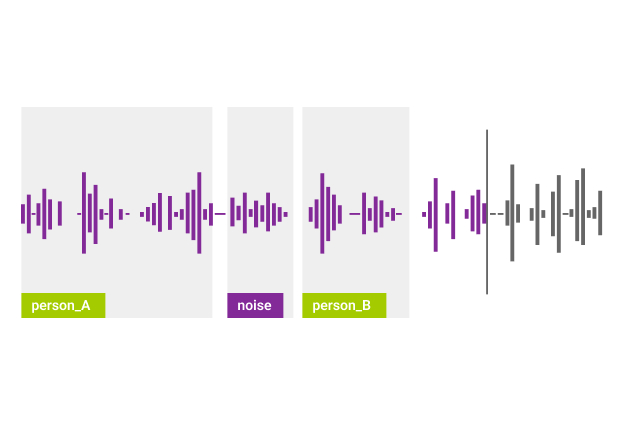
Schallereignis Tracking
Mittels Schallereignis Tracking kann die Leistung von ML-Systemen bei Erkennung von Schallereignissen (Sound Event Detection) überprüft werden. Schallereignisse treten in der Realität meist nicht isoliert auf, sondern überschneiden sich häufig erheblich. Bei dieser Aufgabe gibt es keine Kontrolle über die Anzahl überlappender Schallereignisse zu jedem Zeitpunkt, weder in den Training noch in den Test-Audiodaten. Das Erkennen solcher überlappender Schallereignisse wird als polyphones SED bezeichnet.
Sprache-zu-Text-Transkription
Die Transkription von Sprache in Text ist ein wichtiger Bestandteil der Entwicklung von NLP-Technologien. Dabei geht es nicht nur darum, aufgezeichnete Sprache in Text zu transkribieren, sondern auch die Wörter und Laute, die die Person ausspricht, sorgfältig zu beschriften. Korrekte Zeichensetzung ist ebenfalls wichtig.
Audioklassifizierung
Bei der Audioklassifizierung handelt es sich um das Anhören und Analysieren von Audioaufnahmen. Anhand dieser Daten sind Maschinen in der Lage, zwischen Geräuschen und Sprachbefehlen zu unterscheiden. Diese Art der Audioannotation ist wichtig bei der Entwicklung virtueller Assistenten, automatischer Spracherkennung und Text-to-Speech-Systemen. Es gibt viele verschiedene Arten von Audioklassifizierung:
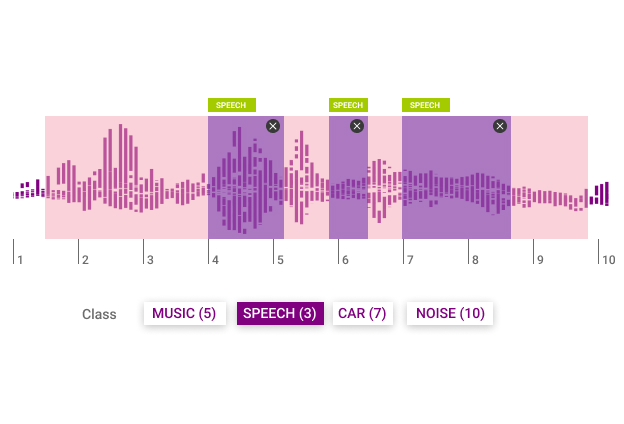
Arten von Audioklassifizierung
- Klassifizierung von akustischen Signalen
- Klassifizierung von Umweltgeräuschen
- Klassifizierung von Musik
- Klassifizierung gesprochener Sprache
- Bei dieser Form der Audio Klassifizierung geht es darum, genau zu identifizieren, wo Schallereignisse aufgezeichnet wurden. Unsere Annotatoren müssen zwischen vielen verschiedenen Umgebungen wie Wohnungen, Schulen, Cafés und vielen weiteren unterscheiden können. Zu verstehen, wo Schallereignisse stattfinden, ist für die Pflege von Soundbibliotheken, für Audio-Multimedia und die Entwicklung von Überwachungssystemen nützlich.
- Wie der Name schon sagt, müssen die Daten Annotatoren dabei verschiedene Geräusche kategorisieren, die verschiedenen Umgebungen zugeordnet werden können. Beispielsweise gibt es bestimmte Geräusche, die spezifisch für Städte sind, wie Baulärm, Hupen, Sirenen und viele andere Geräusche. Dies ist sehr nützlich für die Entwicklung von Sicherheitssystemen, die Einbruchsversuche erkennen können, aber auch für Predictive Maintenance.
- Es gibt viele Kategorien, nach denen Musik klassifiziert werden kann (nicht nur Genre), zum Beispiel welche Instrumente wann spielen, nach Ensembles, Sprache, räumlicher Zuordnung und viele weiteren. Musik zu klassifizieren und zu annotieren ist sehr nützlich, um große Musikbibliotheken zu organisieren und präzisere User Empfehlungen zu geben.
- Bei der Klassifizierung und Annotation gesprochener Sprache werden kleine Details wie Dialekt oder Semantik identifiziert und annotiert. Dies ist sehr wichtig für Chatbots und virtuelle Assistenten, um menschliche Sprache besser zu verstehen.
Klassifizierung von akustischen Signalen
Klassifizierung von Umweltgeräuschen
Klassifizierung von Musik
Klassifizierung gesprochener Sprache
- Bei dieser Form der Audio Klassifizierung geht es darum, genau zu identifizieren, wo Schallereignisse aufgezeichnet wurden. Unsere Annotatoren müssen zwischen vielen verschiedenen Umgebungen wie Wohnungen, Schulen, Cafés und vielen weiteren unterscheiden können. Zu verstehen, wo Schallereignisse stattfinden, ist für die Pflege von Soundbibliotheken, für Audio-Multimedia und die Entwicklung von Überwachungssystemen nützlich.
- Wie der Name schon sagt, müssen die Daten Annotatoren dabei verschiedene Geräusche kategorisieren, die verschiedenen Umgebungen zugeordnet werden können. Beispielsweise gibt es bestimmte Geräusche, die spezifisch für Städte sind, wie Baulärm, Hupen, Sirenen und viele andere Geräusche. Dies ist sehr nützlich für die Entwicklung von Sicherheitssystemen, die Einbruchsversuche erkennen können, aber auch für Predictive Maintenance.
- Es gibt viele Kategorien, nach denen Musik klassifiziert werden kann (nicht nur Genre), zum Beispiel welche Instrumente wann spielen, nach Ensembles, Sprache, räumlicher Zuordnung und viele weiteren. Musik zu klassifizieren und zu annotieren ist sehr nützlich, um große Musikbibliotheken zu organisieren und präzisere User Empfehlungen zu geben.
- Bei der Klassifizierung und Annotation gesprochener Sprache werden kleine Details wie Dialekt oder Semantik identifiziert und annotiert. Dies ist sehr wichtig für Chatbots und virtuelle Assistenten, um menschliche Sprache besser zu verstehen.
Klassifizierung von akustischen Signalen
Klassifizierung von Umweltgeräuschen
Klassifizierung von Musik
Klassifizierung gesprochener Sprache
Multi-Label Audio Annotation
Bei Multi-Label Audio Annotation werden mehrere Labels platziert, um überlappende Schallereignisse in zeitlich komplexen Klanglandschaften zu identifizieren. Für Multi-Label Audio Annotation gibt es drei verschiedene Methoden:
Binäres Labelling
Binäres Labelling gibt an, ob eine bestimmtes vorgegebenes Schallereignis in einer Aufnahme vorhanden ist oder nicht. Bei dieser Methode gibt es lediglich positive und negative Labels.
Einstufiges Multi-Labeling
Bei einstufigem Multi-Labeling wird den Data Annotatoren eine Liste mit Schallereignissen gegeben und es werden alle in der Aufnahme vorkommenden Schallereignisse annotiert.
Zweistufiges hierarchisches Multi-Labeling
In der ersten Stufe identifizieren Annotatoren anhand einer Liste von Schallklassen Schallereignisse, die den Klassen entsprechen. In einer zweiten Stufe wird dasselbe von einem weiteren Annotator wiederholt. Auf diese Weise erhält man explizit positive und implizit negative Labels.





Arbeiten Sie mit führenden Spezialisten an Ihrem KI/ ML-Projekt
Unser kleinster Projektumfang liegt bei 735 produktiven Arbeitsstunden pro Monat. Das entspricht 5 Data Annotation Spezialisten, die jeden Monat an einem Projekt arbeiten.