Textannotation
recognized: textEine schnelle und qualitativ hochwertige Text Annotation
zu einem guten Preis-Leistungsverhältnis garantiert
den Erfolg Ihres Projektes.
Über 8 Jahre Erfahrung
und 2000 Data Annotatoren stehen Ihnen zur Verfügung.
KOSTENLOSE PILOTS VERFÜGBAR

OCR
Optische Zeichenerkennung (OCR) dient dazu, ein Bild von einem Text in ein maschinenlesbares Textformat umzuwandeln. Die Technologiemacht das erneute Abtippen von Dokumenten überflüssig, optimiert Speicherkapazitäten und macht die enthaltenen Informationen einem breiteren Publikum zugänglich. Texterkennungssoftware wird bereits in der Finanzwirtschaft, dem Rechtswesen, dem Gesundheitswesen und vielen anderen Branchen eingesetzt.Wir können Ihnen eine Datenbank zur Verfügung stellen, mit der Sie Ihre Algorithmen für maschinelles Lernen trainieren können, um alle Arten von Zeichen zu erkennen.

-
130
Projects
-
100
Satisfied Clients
-
2000
Employees
-
20
Countries

Transkription
Um den größten Mehrwert aus den Daten herauszukitzeln, benötigen Sie möglicherweise eine akkurate Transkription innerhalb eines bestimmten Zeitraums. Unsere OCR-Transkriptionsdienste werden von erfahrenen Fachleuten durchgeführt. In Kombination mit soliden Projektmanagement Kompetenzen und rigoroser Qualitätskontrolle zu einem guten Preis-Leistungsverhältnis, können Sie sich auf den Kern Ihres Produktes konzentrieren und sicher sein, dass unsere hochwertigen und zeitnahen Transkriptionen Ihren Erfolg auf eine solide Grundlage stellen.

Textklassifikation und Text Tagging
Bei der Textklassifizierung werden je nach Inhalt bestimmte Tags oder Kategorien zugewiesen. Sie bildet die Grundlage für das Trainieren von Machine-Learning-Modellen, die in der Lage sind, große Mengen unstrukturierter Texte zu organisieren und ihnen wichtige Informationen zu entnehmen. Praktische Einsatzfelder finden sich bei der Spam Erkennung oder Sentiment Analysis. Textklassifizierung kann wertvolle Erkenntnisse aus unterschiedlichen Quellen ermöglichen, indem es Informationen aus Social-Media, dem Kundenservice, Kundenfeedback und vielen anderen Quellen extrahiert. Eine solche Datenflut zu verstehen, kann äußerst zeitaufwändig sein. Mit ordentlicher Textklassifizierung ist dies schnell erledigt.

Arbeiten Sie mit führenden Spezialisten an Ihrem KI/ ML-Projekt

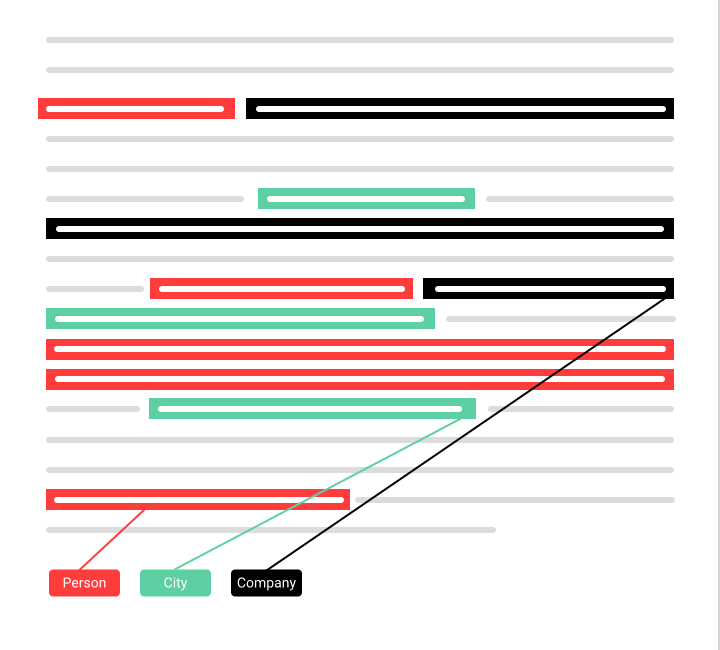
Eigennamenerkennung (Named Entity Recognition)
Named Entity Recognition oder Eigennamenerkennung dient dazu, Eigennamen (benannte Entitäten) in natürlichsprachigen Texten automatisiert zu erkennen und in vordefinierte Kategorien einzuordnen Haben Sie sich jemals gefragt, auf welchen Websites Ihr Unternehmen erwähnt wird? Tatsächlich muss es sich nicht einmal um Ihr Unternehmen handeln, sondern vielmehr um ein Produkt, den Namen eines Mitarbeiters oder eine andere Entität. Mit Named Entity Recognition können solche Entitäten aus großen Textmengen extrahiert und Meta-Informationen hinzugefügt werden. Anwendungen finden sich im Customer Relationship Management oder im Produktmanagement.
Sentiment Analyse
Stellen Sie sich einen Computer vor, der eine zu einem beliebigen Thema geäußerte Haltung in Texten versteht. Jüngste Fortschritte im maschinellen Lernen haben das, was einst eine Science-Fiction-Fantasie war, Realität werden lassen. Grundlage für Machine Learning Modelle sind dabei Annotierte Daten. Sentimentanalyse kann aber auch durch Annotation selbst erfolgen. Identifizieren lässt sich:
• Polarität – Ob die Haltung positiver oder negativer Natur ist
• Thema – Genau das, was im Text besprochen wird
• Sprecher – Wer ist die Person, die ihre Haltung äußert?
