QUALITÄTSSTEIGERUNG VON TRAININGSDATEN FÜR EIN TIER-1 AUTOMOBILZULIEFERER

Kundenprofil
Branche: Automobilindustrie
Land: Deutschland
Unternehmensgröße: 2.000+ Mitarbeiter
Beschreibung des Kunden
Als in Sachen Innovation und Präzisionstechnik traditionsreiches Unternehmen setzt es weltweit Maßstäbe für Qualität in der Automobilindustrie. Engagement für Spitzentechnologie und nachhaltige Praktiken untermauern den Einsatz für die Gestaltung zukünftiger Mobilität.
Einleitung
Unter dem Einsatz modernster Techniken und unseres tiefen Wissens über Qualitätskontrolle in der Datenannotation haben Quality Match in Kooperation mit Mindy Support für einen führenden deutschen Tier-1 Automobilzulieferer die Qualität seiner Datensätze für das Training von Sensoren überprüft. Hierbei handelte es sich um Objekterkennung für ein Advanced Driver Assistance System (ADAS) für Level-3-Fahren. Um die annotierten Daten zum Trainieren des KI-Systems zur Erkennung von Fußgängern auf der Straße zu optimieren, war rigorose Qualitätskontrolle erforderlich. Dieser Prozess war von entscheidender Bedeutung für die Identifizierung und Behebung von Fehlern und stellte die Integrität zukünftiger Datensätze sicher.
Beschreibung des Projekts

Für dieses Projekt wurden mehrere Datensätze bereitgestellt, die bereits von einem anderen Dienstleister annotiert wurden. Mindy Support und Quality Match analysierten und verglichen die Qualität der Annotationen in den verschiedenen Datensätzen und kennzeichneten Annotationsfehler zur Korrektur. Bei dieser Qualitätskontrolle lag der Fokus der Bewertung der vorhandenen Annotationen auf drei wichtigen in der Qualitätssicherung gebräuchlichen Metriken: Falsch negative Annotationen (FN), falsch positive Annotationen (FP) und geometrische Genauigkeit. Eine Priorität des Kunden war auch eine Prüfung auf verdeckte Objekte (solche, die aufgrund eines behindernden Objekts nicht vollständig sichtbar sind).
Die annotierten Datensätze enthielten 2D-Begrenzungsrahmen um Fußgänger, die überprüft werden mussten. Um die oben genannten Qualitätsmetriken abzuleiten, mussten zuvor folgende Fragen beantwortet werden.
- Befindet sich eine Person in dem Fahrzeug?
- Handelt es sich bei dem Objekt um eine Darstellung (Poster, Werbetafeln, Bilder, Schaufensterpuppe, Statue), eine Spiegelung, ein Tier oder etwas Mehrdeutiges / nicht erkennbar?
- Ist der Fußgänger innerhalb des 2D-Begrenzungsrahmens vollständig sichtbar?
- Wie viele Fußgänger sind innerhalb des 2D-Begrenzungsrahmens sichtbar?
Bereitgestellte Data Annotation Lösung
Mindy Support und Quality Match arbeiteten bei diesem Projekt zusammen und nutzten ihre gemeinsame Expertise, ihr Fachwissen über Datenqualität und ihre Erfahrung in der Annotation von in der Automobilindustrie relevanten Daten. Mindy Support brachte seine Erfahrung aus unzähligen Projekten rund um das Thema Data Annotation für autonomes Fahren ein, zum Beispiel über alle relevanten Datenformate, Annotationstypen, Klassen und Attribute sowie Qualitätsmetriken. Quality Match steuerte ein innovatives Tool für Qualitätssicherung bei. Dabei werden einfache Fragen über bereits annotierte Daten in einem speziellen Entscheidungsbaum gestellt, der die Überprüfung der Annotationsqualität mit statistischen Methoden erzwingt.
In einem ersten Schritt zerlegten Quality Match und Mindy Support die mit dieser Qualitätssicherung einhergehenden komplexen Tätigkeiten in einzelne, eindimensionale Entscheidungen, sogenannte „Nano-Aufgaben“. Dieser Ansatz reduziert die Belastung des individuellen Testers, indem er seinen Fokus auf einzelne Annotationen und einen Aspekt der Qualitätsmetriken konzentrieren kann.

Anstatt den Tester zu bitten, ein ganzes Bild auf einmal zu verarbeiten und zu prüfen, wird jede Entscheidung oder jedes Attribut innerhalb des Bildes als separate, isolierte Aufgabe behandelt. Dies minimiert die Wahrscheinlichkeit, dass Fehler oder Ungenauigkeiten aufgrund kognitiver Überlastung übersehen werden und trägt dazu bei, dass Mehrdeutigkeiten oder Grenzfälle leichter erkannt werden. Die einzelnen Nanoaufgaben werden als logischer Entscheidungsbaum strukturiert, an dessen Anfang allgemeine Fragen stehen und der sich auf der Grundlage vorangegangener Antworten in Details verästelt. So werden unnötige Fragen vermieden und der Zeit- und Ressourcenaufwand für die Qualitätskontrolle optimiert.
Die mehrmalige Bearbeitung derselben Nanoaufgaben durch unterschiedliche Tester ermöglicht eine statistische Analyse der Ergebnisse, die statistische Garantien für die Validität der Ergebnisse liefert, die Grundlage für die Identifikation und Beseitigung von Mehrdeutigkeiten bildet und mit Belegen und Fakten Zertifizierbarkeit erleichtert. Dies ist besonders relevant für die Einhaltung des sich derzeit noch in der Entwicklung befindlichen ISO-5259-2 Standards (Datenqualität für Analytik und maschinelles Lernen (ML) in der künstlichen Intelligenz).
Der Einsatz von Entscheidungsbäumen bei der Qualitätskontrolle half auch die Ursache für Meinungsverschiedenheiten zu ermitteln, wenn verschiedene Tester widersprüchliche Angaben machten. Das kommt zum Beispiel vor, wenn das Objekt verschwommen oder dunkel ist oder die Frage selbst unklar ist. Dadurch, dass die Ursache der Meinungsverschiedenheit ermittelt werden kann, kann sie oft behoben werden, sodass die Genauigkeit und Effizienz der Qualitätssicherung verbessert werden. Für dieses Projekt wurde jede Nanoaufgabe von fünf unterschiedlichen Testern bearbeitet.
Ergebnisse
Die Analyse der Datensätze auf falsch positive Annotationen (FP), falsch negative Annotationen (FN), geometrische Genauigkeit und Anteil verdeckter Objekte lieferte folgende Ergebnisse:
(1) In einem Datensatz lag der Anteil falsch negativer Annotationen bei 17%
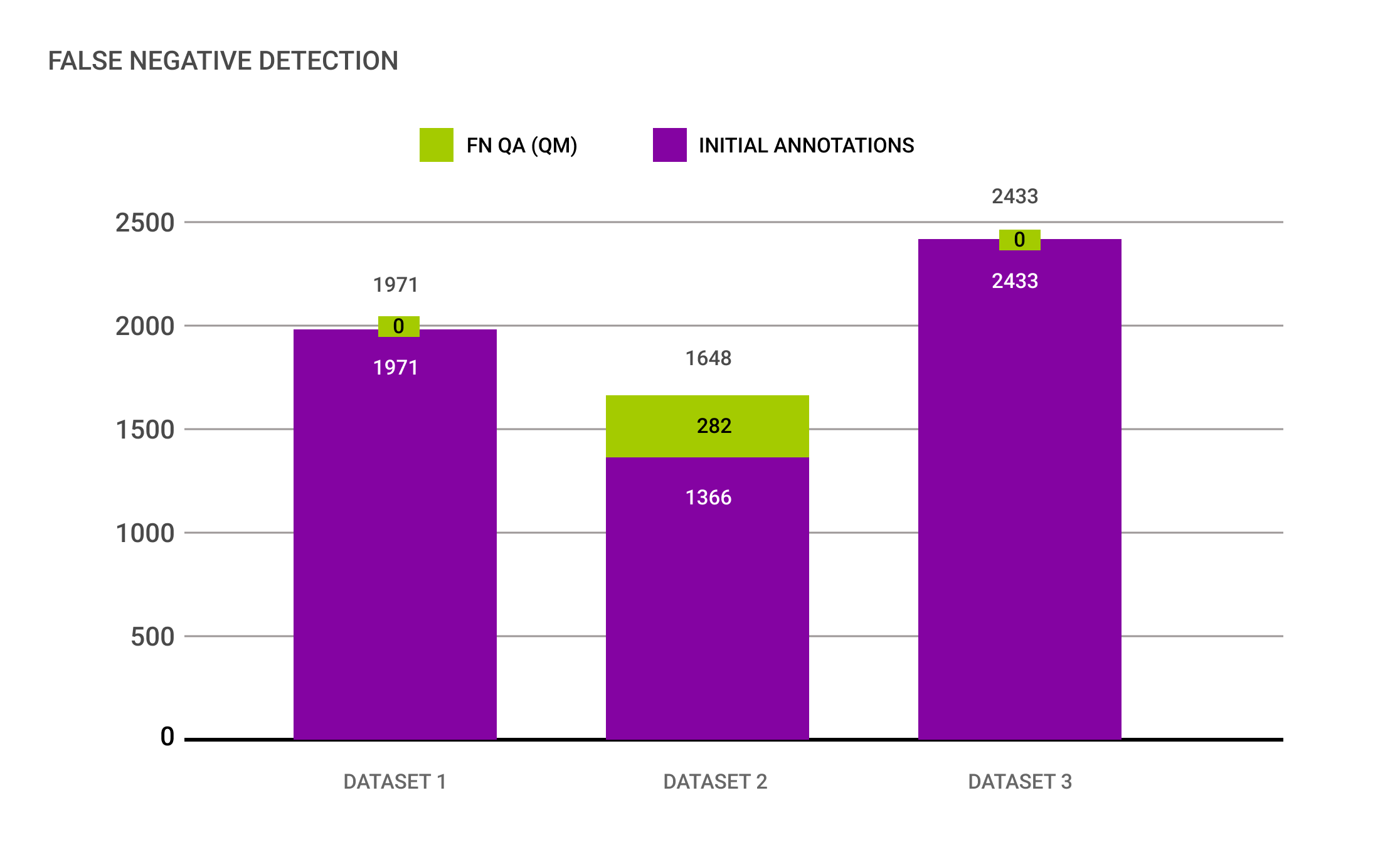
Die übrigen Datensätze wiesen niedrigere Anteile falsch negativer Annotationen auf. Alle Befunde wurden mit dem Automobilzulieferer geteilt, um mögliche Verbesserungen für zukünftig zu annotierende Datensätze zu besprechen.Dies führte zu einer Feinabstimmung über Taxonomie, um für mehr Klarheit zu sorgen, welche Arten von Objekte in die Annotation Eingang finden.
(2) Alle Datensätze enthielten einen geringen Anteil falsch positiver Annotationen, 1% im Schnitt
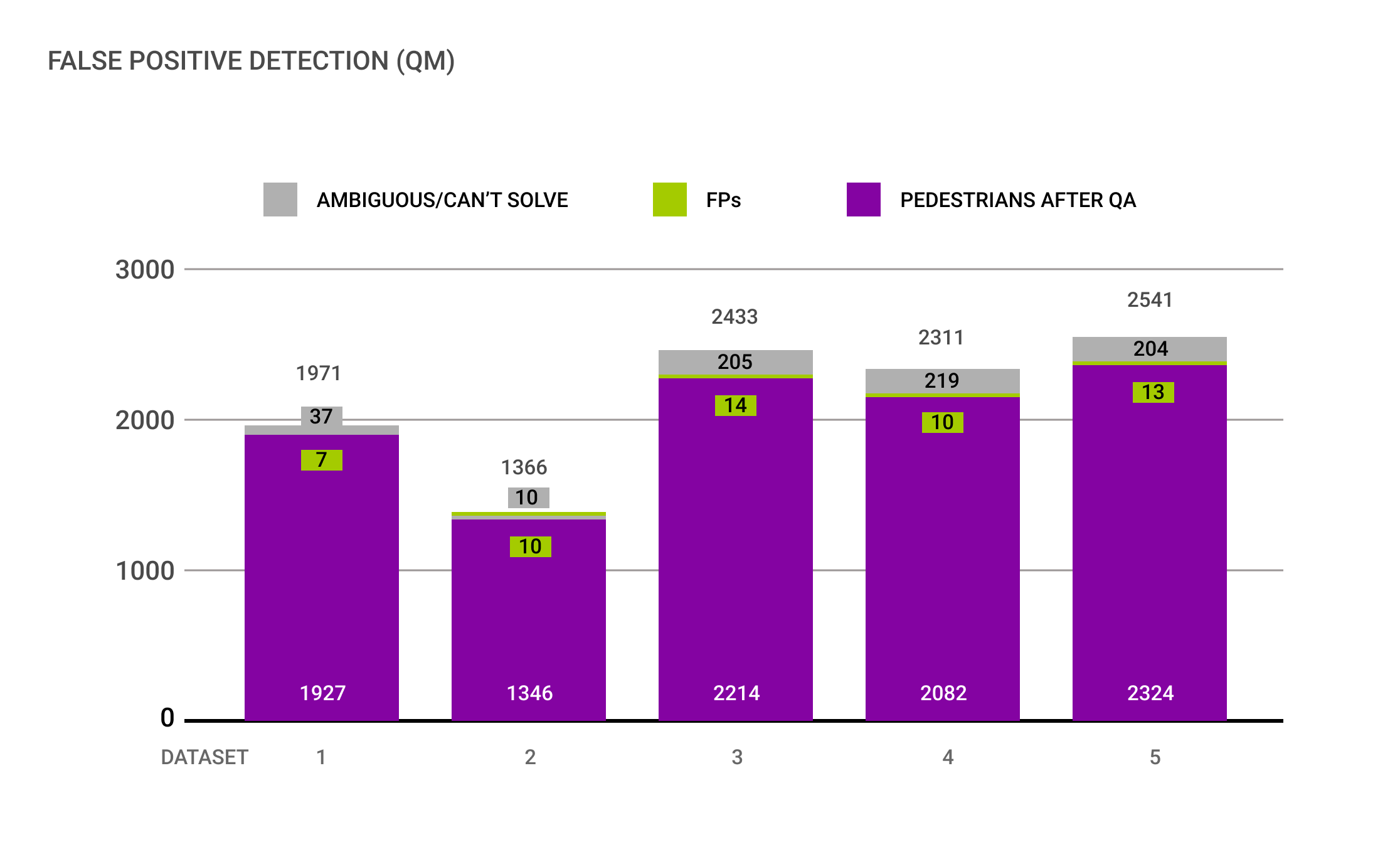
Die Mehrzahl festgestellter falsch positiver Annotationen entpuppten sich als Reiter, die als Fußgänger gekennzeichnet wurden. Als Resultat wurde vorgeschlagen, die beiden Klassen in der Taxonomie zu unterscheiden.
Der von Quality Match vorgeschlagene innovative „Repeat“ Ansatz, Annotationen mehrmals durch unterschiedliche Tester zu prüfen, ermöglichte es 10% mehrdeutige Annotationen zu identifizieren. Diese werden durch kleine oder verschwommene Annotationen verursacht und werden im Rahmen einer regulären Qualitätskontrolle häufig außer Acht gelassen. Eine Validierung der Qualität liefert aber Hinweise darauf, ob ein Trainingsdatensatz zu mehrdeutig ist, um die Leistung des ML-Modells zu verbessern.
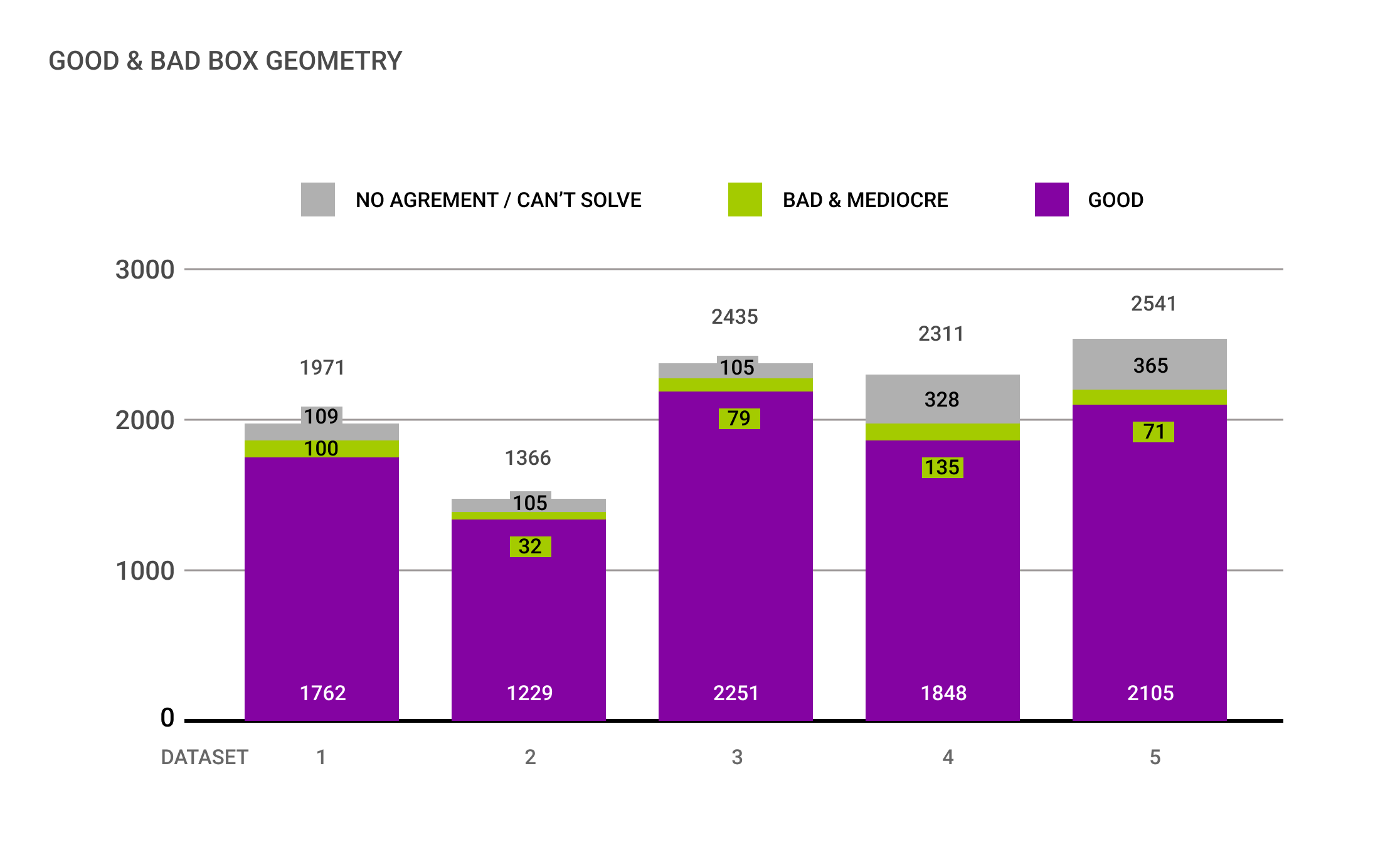
(3) 2-6% der 2D-Begrenzungsrahmen waren geometrisch ungenau
(4) Die Einstufung verdeckter Objekte variierte stark zwischen Datensätzen, um bis zu 200%
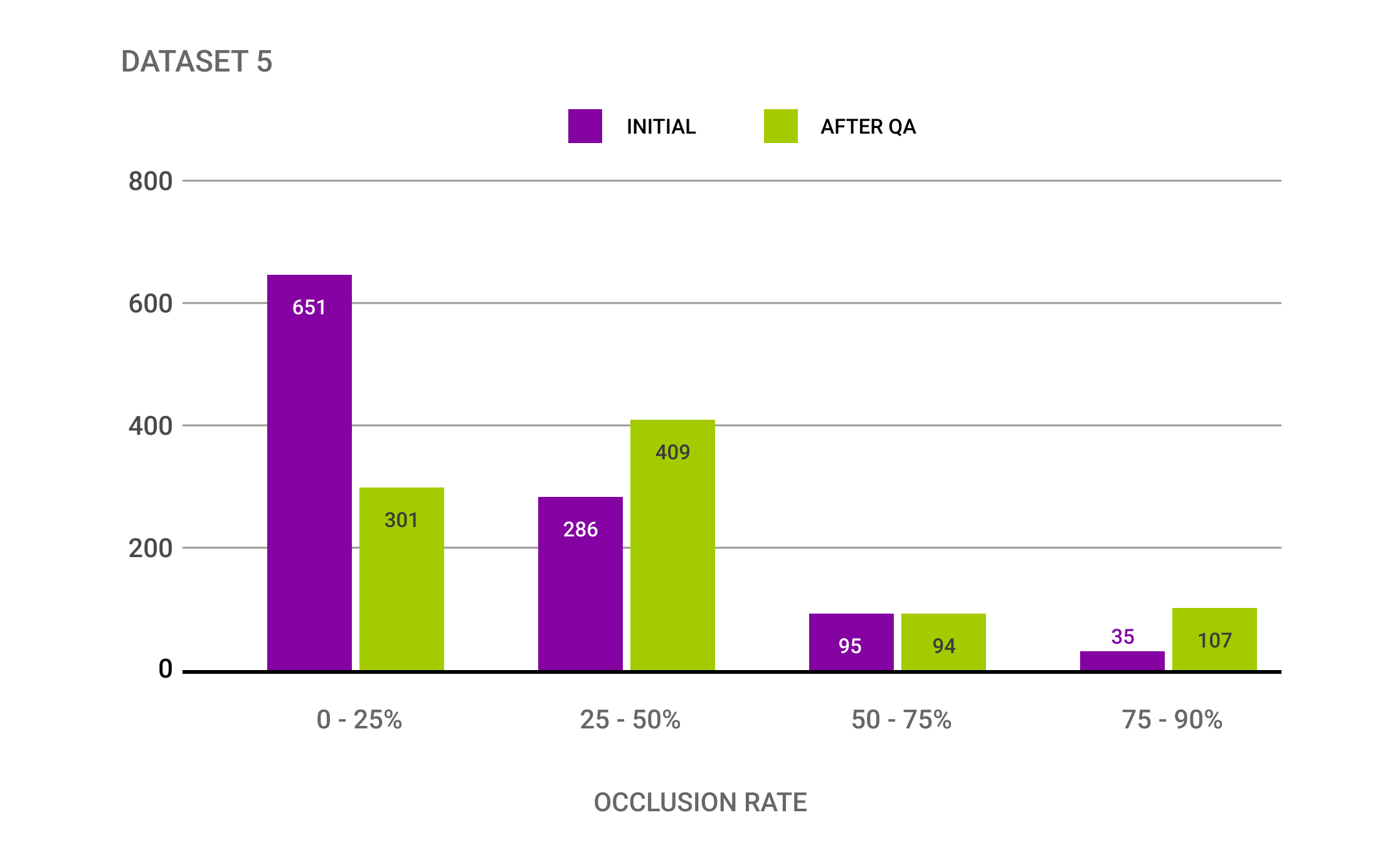
Die obige Grafik zeigt signifikante Unterschiede bei der Einstufung verdeckter Objekte in den ursprünglichen Daten und nach der Qualitätskontrolle von Quality Match und Mindy Support. In der Kategorie 75-90% Verdeckung des Objekts zeigte sich ein 205% Anstieg an Annotationen in dieser Kategorie. Weitere Untersuchungen ergaben, dass die Vorgaben für die Einstufung in die verschiedenen Kategorien nicht genügend Beispiele enthielten, wie Verdeckung in diesen Kategorien aussieht, sodass Varianz auftrat.
Zusammenfassung

Die wichtigste Erkenntnis aus der von Mindy Support und Quality Match durchgeführten Qualitätskontrolle besteht darin, dass Inkonsistenzen und unzureichende Beispiele in den Vorgaben zur Annotation zu unterschiedlichen Interpretationen führen können, wie einzelne Aufgaben bei der Annotation erledigt werden sollen. Um solche Probleme zukünftig zu vermeiden wurden dem Kunden Empfehlungen zur Homogenisierung seiner Annotationsrichtlinien gegeben. Neben der Identifikation fehlerhafter Annotationen wurden manche Ursachen für mehrdeutige Annotationen ermittelt.
Beides führt zu einem besseren Verständnis der Datenqualität, die sich auf die Qualität des zu trainierenden ML-Modus auswirkt. Diese tiefe Einsicht in die Qualität der verwendeten Daten spiegelt eine einzigartige Zusammenarbeit zwischen Quality Match und Mindy Support wider, die unser jeweiliges Fachwissen mit innovativen KI-gesteuerten Tools verbindet. Diese Partnerschaft unterstreicht die Wirksamkeit unseres gemeinsamen Ansatzes bei der Erzielung außergewöhnlicher Ergebnisse.
Identifizierte Qualitätsdefizite
- In einem Datensatz lag der Anteil falsch negativer Annotationen bei 17%
- Alle Datensätze enthielten einen geringen Anteil falsch positiver Annotationen 1% im Schnitt
- 2-6% der 2D-Begrenzungsrahmen waren geometrisch ungenau
- Die Einstufung verdeckter Objekte variierte stark zwischen Datensätzen, um bis zu 200%
