Video Annotation
Video Annotation ist eine wichtige Art von Datenannotation
bei der Vorbereitung von Trainingsdatensätzen für Deep-Learning und Machine-Learning Modellen
in der Automobilindustrie, der Games-Branche, bei der Entwicklung von AR/VR Anwendungen
und vielen anderen Bereichen.
Was ist Videoannotation?
Bei der Videoannotation für Machine Learning und Deep Learning Projekte werden Videos in Bilder (Frames) zerlegt und alle Bilder mit verschiedenen Techniken annotiert. Die genaue Anzahl der Bilder, die mit Annotationen versehen werden müssen, hängt von der Länge des Videos und der Bildfrequenz (frames per second) ab. Hat man beispielsweise ein 60 Sekunden langes Video mit einer Bildfrequenz von 60 fps, sind das bereits 3.600 statische Bilder, die annotiert werden müssen. Videoannotation ist schnell ein sehr zeitaufwändiger Prozess, weshalb Medien- und Technologieunternehmen sich oft für eine Kooperation mit Data Annotation Dienstleistern entscheiden.
Herausforderungen bei Video Annotation
Es gibt viele Gründe, warum die Annotation von Videodaten ein anspruchsvoller Prozess ist. Da es sich nicht um statische, sondern um Objekte von Interesse handelt, die sich bewegen, wird es schwieriger, sie korrekt zu annotieren, um präzise Ergebnisse beim Training der Modelle zu erhalten. Zudem sind sehr große Mengen an Annotationen erforderlich. Im oben genannten Beispiel haben wir bereits über die Anzahl der statischen Bilder gesprochen, die in einem 60 sekündigen Video mit 60 fps entstehen (3.600). Stellen Sie sich nun vor, Sie hätten lediglich ein Video, das mehrere Minuten lang ist...oder viele Videos. Der Arbeitsaufwand bei der Annotation vieler Videos steigt exponentiell, sodass anstatt die Video Annotation alleine zu stemmen, die Zusammenarbeit mit Experten sinnvoll ist, die über die erforderlichen Personalressourcen und das technisch-organisatorische Know-How verfügen, um sehr große Datensätze zu Annotieren. Hinzu kommt, dass sich viele Ereignisse, die im Video verfolgt werden müssen, überschneiden können. Dies präzise zu Annotieren stellt eine Herausforderung bei der Annotation dar, da eine Genauigkeit von bis zu Millisekunden erforderlich ist. Hierfür werden technisch spezialisierte Ansätze verwendet.

Video Annotation Dienstleistungen
2D-Begrenzungsbox
Bei dieser Art der Annotation wird in jedem Bild das Objekt von Interesse mit einem zweidimensionalen Rechteck markiert. Dies hilft KI/ML Systemen, dieselben Objekte in der realen Welt korrekt zu identifizieren. 2D-Begrenzungsboxen werden häufig in der Automobilindustrie, der Sicherheitsindustrie und der Medien- und Unterhaltungsbranche verwendet.

3D-Begrenzungsbox
3D-Begrenzungsboxen ermöglichen KI/ML Modellen mehr Einblicke in Objekte in Bildern, insbesondere in deren Länge, Breite und Höhe. Sie enthalten mehr Informationen und sind somit präziser als 2D-Begrenzungsboxen. In der Automobilindustrie werden sie verwendet, um ein Verständnis der Verkehrssituation zu bekommen. Bei der Entwicklung von Algorithmen für den Betrieb von Robotern und Drohnen sind sie ebenfalls wichtig, da diese nicht nur die Objekte und ihre Größe, sondern auch ihre Platzierung im dreidimensionalen Raum und den Abstand zwischen ihnen analysieren müssen.

Linien und Splines
Linien und Splines werden verwendet, um verschiedene Teile eines Bildes voneinander abzugrenzen. Beispiele wären die Abgrenzung von Fahrspuren, Gassen oder Förderbänder in Lagern zu identifizieren oder die Markierung von Nutzflächen in der Landwirtschaft.

Polygone
Polygone sind sehr nützlich, um unregelmäßig geformte Objekte in Bildern zu markieren, die schlecht in 2D-Begrenzungsboxen passen. Mit Polygonen lässt sich die genaue Form und Größe des Objekts abbilden und sie sorgen für eine genauere Lokalisierung. Diese Methode der Annotation wird in der Automobilindustrie verwendet, um alle Objekte auf Straßen zu kennzeichnen.

Landmarks
Bei dieser Methode werden zentrale Punkte über einem Bereich von Interesse platziert. Damit können Variationen in der Gestalt präzise abgebildet werden, um Bewegung zu verfolgen oder Emotionen oder Handgesten zu erkennen. Anwendung finden Landmarks bei der Gesichtserkennung oder in Videospielen.

Labeling / Tagging
Labels und Tags sind schriftliche Markierungen von Objekten in Bildern. Durch Training mit Labels und Tags versehener Bilder können Machine Learning Systeme solche Objekte in der realen Welt identifizieren. Sie helfen aber auch bei der Erkennung und Rekonstruktion von Ereignissen, indem alle Aktionen, die zu einem Ereignis gehören, mit Labels versehen werden.

Klassifizierung
Bei dieser Methode werden bestimmte Ereignisse in Videos klassifiziert oder kategorisiert. Diese Methode ist nützlich, wenn bestimmte Bewegungen oder Handlungen identifiziert werden sollen. Klassifikation kann aber auch auf das gesamte Video angewendet werden, beispielsweise um die Qualität oder Nützlichkeit mit einem Benchmark zu vergleichen oder den Grad der Übereinstimmung mit der Botschaft, die das Video vermitteln sollte, zu messen. Video Klassifizierung findet häufig Anwendung in der Games-Branche, der Sicherheitsindustrie oder Virtual Reality.
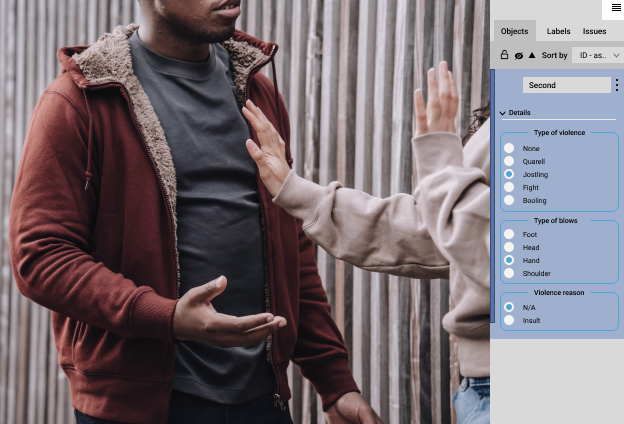
Ereignis Tracking
Beim Tracking von Ereignissen (Event Tracking) geht es nicht darum, die Bilder eines zerlegten Videos selbst mit Annotationen zu versehen, sondern darum, Ereignisse im Video selbst zu lokalisieren und zu kennzeichnen. Dadurch können trainierte KI/ML Modelle Ereignisse von Interesse zuverlässig erkennen. Wenn Gruppen von Labels sich mit mehreren Klassen überschneiden, können die Videos dupliziert werden, um sich überschneidende Ereignisse zu annotieren.
Fallbeispiele für Video Annotation





Arbeiten Sie mit führenden Spezialisten an Ihrem KI/ ML-Projekt
Unser kleinster Projektumfang liegt bei 735 produktiven Arbeitsstunden pro Monat. Das entspricht 5 Data Annotatoren, die jeden Monat an einem Projekt arbeiten.