Feinabstimmung von (M)LLMs (Fine-Tuning)
Bei der Feinabstimmung großer Sprachmodelle werden vorab trainierte Modelle anhand kleinerer, auf das Erlernen einer bestimmten Aufgabe ausgerichteter Datensätze weiter trainiert, um generelle Fähigkeiten zu verfeinern und die Leistung für diese bestimmte Aufgabe oder Domäne zu verbessern. Es geht darum, allgemeine Modelle in spezialisierte Modelle umzumünzen. Dadurch wird die Lücke zwischen generischen Modellen und den einzigartigen Anforderungen spezifischer Anwendungen geschlossen und sichergestellt, dass das Sprachmodell genau den menschlichen Erwartungen entspricht.


Diensleistungen für das Fine-Tuning von (M)LLMs
Für Fine-Tuning werden qualitativ hochwertige, ausreichend große und repräsentative Trainingsdaten benötigt, die zur bestimmten Aufgabe/Domäne passen. Ansonsten droht Überanpassung, Unteranpassung oder Verzerrung des Modells, was dessen Generalisierbarkeit und Robustheit beeinträchtigt. Wir bieten alle Data Annotation Dienstleistungen aus einer Hand, die Sie für die Feinabstimmung Ihres (M)LLMs benötigen:
Textklassifizierung
Jeder Textprobe wird mit einer Kategorie oder einem Label gekennzeichnet.
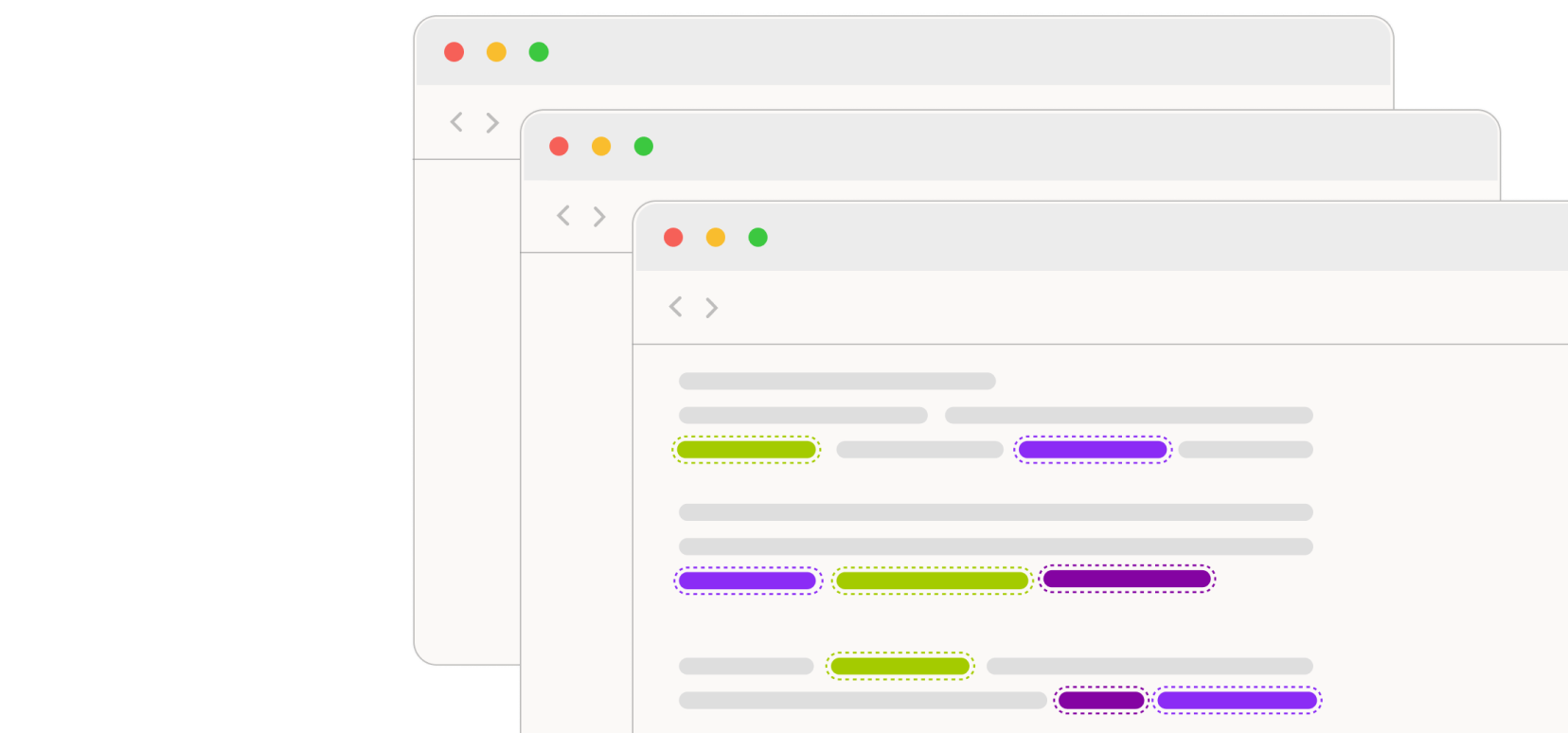
Kennzeichnung von Sequenzen (Sequence Labeling)
Bei Sequence Labeling werden die Komponenten einer Sequenz, z. B. Wörter oder Phrasen in einem Satz, identifiziert und gekennzeichnet. Häufig dient sie als Vorbereitung für weitere NLP-Annotationen, beispielsweise der Markierung von Wortarten oder der Erkennung benannter Entitäten, und ist eine Schlüsselkomponente vieler NLP-Anwendungen.

Sentimentanalyse
Deep-Learning Modelle wie Transformer erfordern viele Trainingsdaten, in denen Texte anhand der in ihnen ausgedrückten subjektiven Stimmungen (positiv, negativ, neutral) von Data Annotatoren klassifiziert wurden, häufig mit einem Score, der die Intensität der Stimmung beschreibt.
Kontent-Generierung für generative Prompts
Fragen und Antworten ist eine wichtiges Anwendungsgebiet von LLMs, beispielsweise bei Chatbots. LLMs können mit einem Fragen-Antwort-Datensatz feinabgestimmt werden, was auch als Instruct-Tuning bezeichnet wird. Wir können domänenspezifische Daten (Kontext) für Ihre Prompts bereitstellen, um genaue domänenspezifische LLM-Antworten zu erhalten.
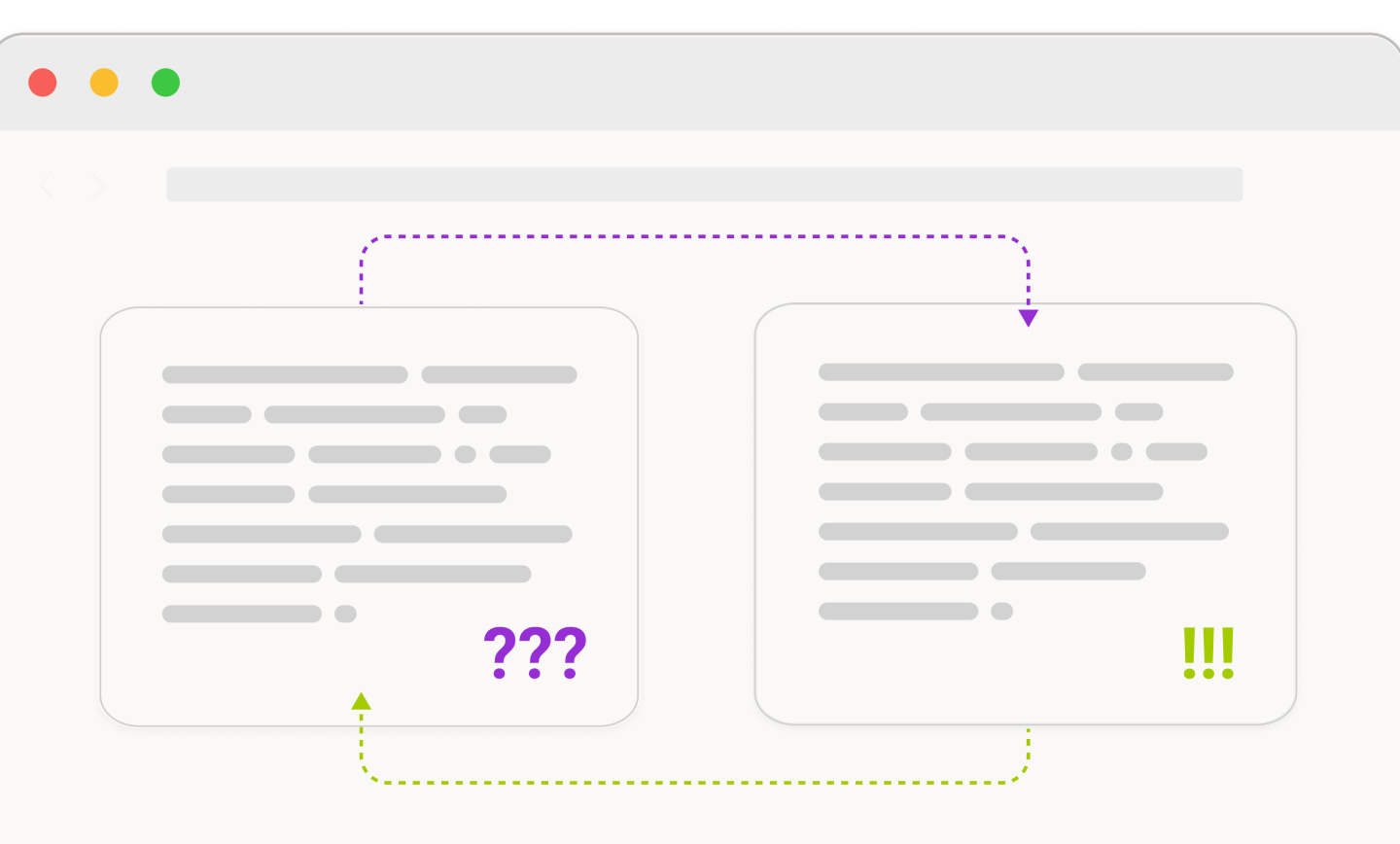
Textlokalisierung
Wir passen Ausgangstexte und Prompts an sozio-kulturelle Besonderheiten, bestimmte Schreibstile, domänenbezogene Inhalte oder sprachlichen Nuancen so an, dass sie für die Feinabstimmung von LLMs verwendet werden können, um in kontextbezogenen Lernszenarien eine bessere Leistung zu erzielen.

Textzusammenfassung
Um optimale Ergebnisse bei Zusammenfassungen für bestimmte Branchen oder Themen zu erzielen, kann eine Feinabstimmung oder eine zeitnahe Anpassung von LLMs erforderlich sein. Wir stellen von Menschen verfasste Referenz-Zusammenfassungen bereit, die zum Vergleich oder für eine Feinabstimmung verwendet werden können.
Warum arbeiten unsere Kunden mit uns?
Es gibt viele verschiedene Gründe, warum ein externer Data Annotation Anbieter wie Mindy Support für Fine-Tuning von (M)LLMs gewählt wird. Dazu gehören:





Globale Präsenz
Die Erstellung von Trainingsdaten für LLM und MLLM erfordert häufig Datenverarbeitung in verschiedenen Sprachen. Unter Rückgriff auf weltweit verteilte Standorte können wir multilinguale LLM Fine-Tuning Teams zusammenstellen, die leicht und problemlos für LLM-Lösungen erforderliche Trainingsdatensätze kennzeichnen, sei es für RLHF, überwachtes Lernen oder andere Methoden.
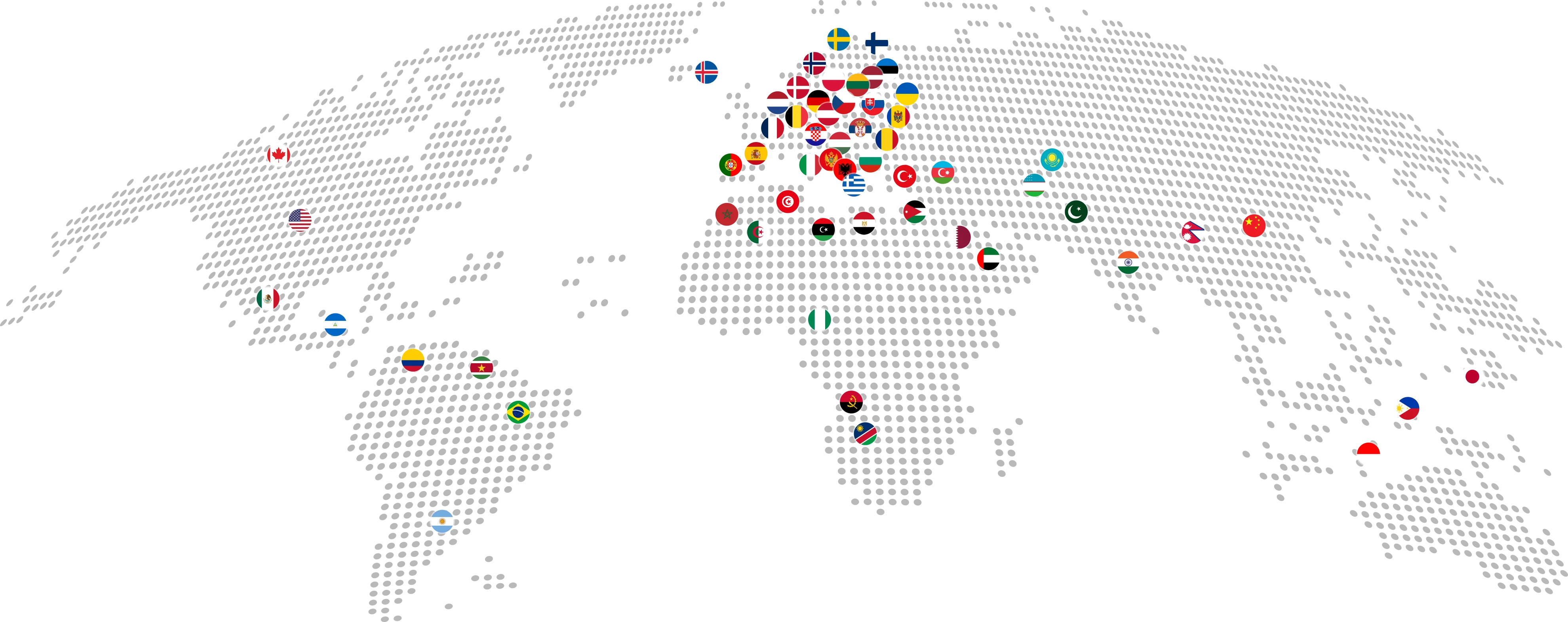
Fallstudien









Referenzkunden




Kundenmeinungen

Guilia M
Anyline, Österreich
Dank Mindy Support war der Kunde in der Lage, mehrere maßgeschneiderte mobile OCR-Scanlösungen fristgerecht zu liefern. Sie waren gründlich und reagierten schnell, mit klarer Kommunikation. Ihre beeindruckendste Leistung war die Erstellung von Lösungen innerhalb von Stunden.

Dr. Henning Lategahn
Atlatec GmbH, Deutschland
Wir arbeiten jetzt schon seit einiger Zeit mit Mindy zusammen. Sie unterstützen unsere Teams in Deutschland bei der 3D-Kartografie. Ihre Arbeit ist von unschätzbarem Wert und hilft uns, pünktlich und innerhalb unseres Budgets qualitativ hochwertige Ergebnisse zu erzielen. Sie sind ein vollwertiger Teil unseres Teams. Danke, Mindy.

Nick D.
Viu More, Belgien
Dank Mindy Support hat der Kunde ein effektives Modell entwickelt, das es ihm ermöglicht, die verschiedenen Abfallarten zu unterscheiden. So konnten sie innerhalb von zwei Wochen über 1.000 Bilder mit Anmerkungen versehen. Die Zusammenarbeit mit dem Team ist einfach - es ist aufgeschlossen für Feedback, sympathisch und kommunikativ.

Emma Schuster
Sweatcoin, Vereinigtes Königreich
Das Mindy Support Team verstand seine Rolle sofort und konnte alle Bedürfnisse ihres Kunden erfüllen. Sie bemühen sich proaktiv um Feedback und sind äußerst reaktionsschnell. Mit guten Projektmanagement-Kompetenzen konnten sie einen tollen Service und effektive Arbeitsabläufe sicherstellen. Immer ansprechbar ist das Mindy Team auch stets zur Stelle, wenn es gebraucht wird.

Antoine S.
Kili Technology
Der Kunde war mit der Leistung von Mindy Support sehr zufrieden. Die Qualität der Kommentare und das Arbeitstempo waren beeindruckend. Sie sind reaktionsschnell und organisiert und ermöglichen einen nahtlosen Arbeitsablauf, der eine langfristige Partnerschaft fördert.

Tyler M.
Superb AI
Das Beeindruckendste an Mindy Support ist ihre Fähigkeit, Schnelligkeit mit Präzision zu verbinden und dabei die Kosteneffizienz zu wahren. Ihre Fähigkeit, Projektanforderungen schnell zu erfassen und qualitativ hochwertige Anmerkungen innerhalb strenger Fristen zu liefern, ist lobenswert und hat maßgeblich zum Erfolg unserer Projekte beigetragen.

René Bolier
OnRecruit, Niederlande
Für uns bot Mindy Support ein gutes Return on Investment. Viele Treffen mit potenziellen Neukunden wurden allein durch ihre Arbeit zum Erfolg. Auf persönlicher Ebene war die Zusammenarbeit mit Tetiana und Evgenia sehr angenehm. Sollten wir in diesem Bereich wieder Fachwissen benötigen, wäre Mindy Support auf jeden Fall unser erster Ansprechpartner.