DeDeepseek x LLMs: Eine Kurzübersicht
Large language models (LLMs) sind ein relativ neuer Anwendungsbereich künstlicher Intelligenz, der sich rasant weiterentwickelt. Mittlerweile sind sie in der Lage, Text auf fast menschlichem Niveau zu verstehen und zu generieren und ermöglichen Interaktionen zwischen Mensch und Technologie in Form von Chatbots oder Suchmaschinen. Die Integration von LLMs mit Deepseek ist ein hervorragendes Beispiel hierfür, da die Plattform über aktuelle intelligente Suchfunktionen hinausgeht. In diesem Post thematisieren wir, was LLMs sind und welche Praktiken Deepsek anwendet, um Informationen bereitzustellen.
Was sind Large Language Models?
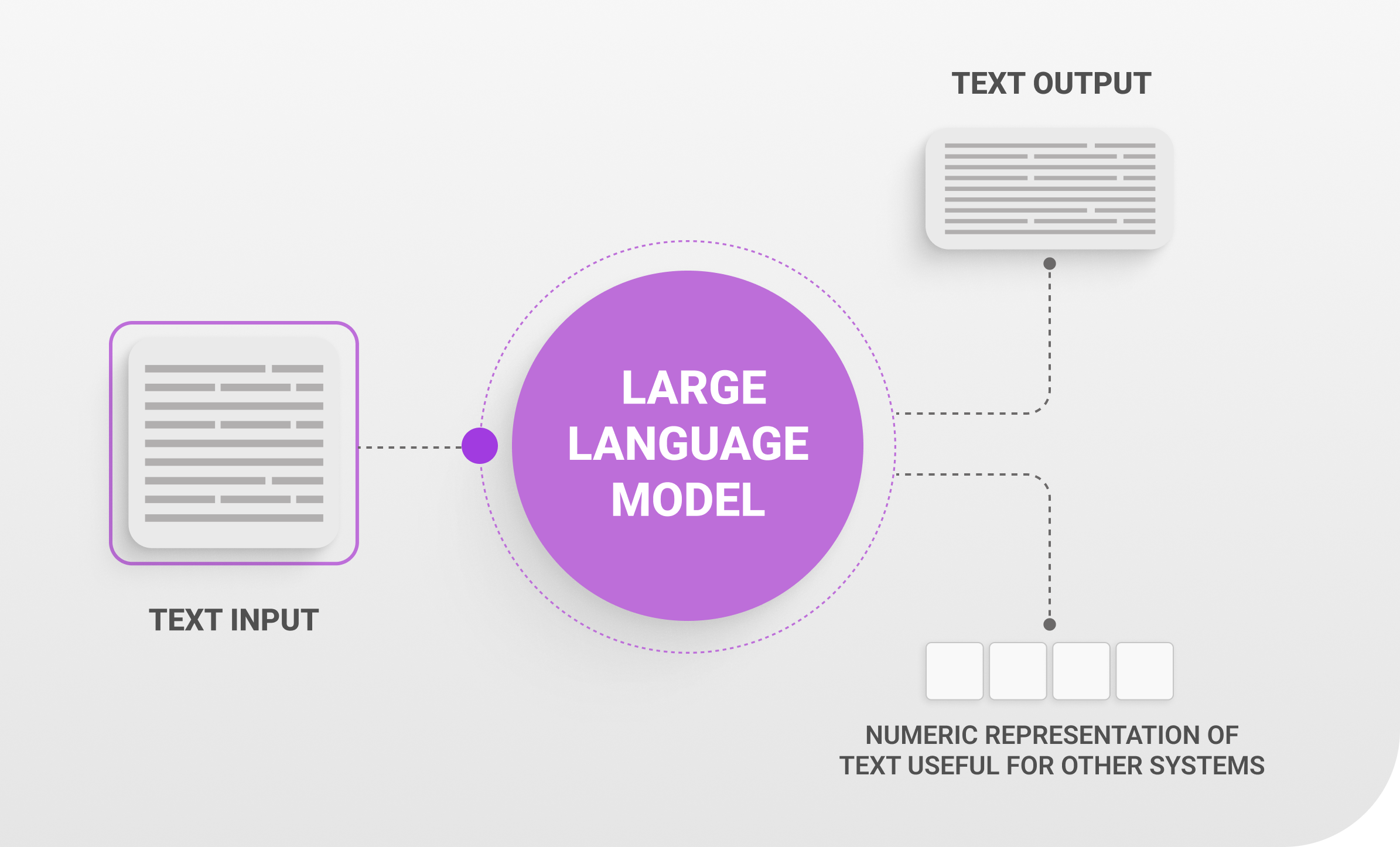
Große Sprachmodelle sind eine Klasse künstlicher Intelligenz, die darauf spezialisiert ist, natürliche Sprachinhalte zu interpretieren und zu produzieren. Durch umfangreiches Training aus Büchern und Artikeln auf Websites sowie zahlreichen Textquellen lernen diese Modelle sequentielle Wortvorhersage, mit der sie Programmiercode generieren, Aufsätze schreiben und Fragen beantworten können.Der Aspekt „groß“ bezieht sich dabei auf ihren Umfang. Modelle wie GPT-4 von OpenAI und PaLM von Google verfügen über Milliarden von Parametern, wodurch sie ein nuanciertes Verständnis und Kontextbewusstsein entwickeln können. Daher sind sie besonders gut für die folgenden Anwendungsfälle geeignet:
- Content Generierung – Large Language Models (LLMs) verarbeiten natürliche Spracheingaben, um vielfältige, hochwertige Inhalte zu erstellen, darunter Websites und kreative Werke. Sie werden beispielsweise genutzt, um Social Media Nachrichten und anderen Marketing Content oder Produktbeschreibungen zu erstellen. Kreative Köpfe nutzen Sie auch, um Ideen für Geschichten zu bekommen, Blaupausen für Drehbücher zu entwickeln oder für bestimmte Zielgruppen relevante Brand Messages zu identifizieren.
- Übersetzungen – LLMs sind gut darin natürliche Sprache von einer Sprache in die andere zu übersetzen und dabei den ursprünglichen Kontext und die ursprüngliche Bedeutung zu bewahren. Sie übersetzen Texte also relativ originalgetreu, indem sie idiomatische Ausdrücke sowie kulturelle Feinheiten verstehen und berücksichtigen. Dadurch entsteht das Gefühl eines natürlichen, nachvollziehbaren Textes. Sie können problemlos und schnell zwischen verschiedenen Sprachen übersetzen und eignen sich für Content Lokalisierung für internationale Zielgruppen.
- Sentimentanalyse – Mithilfe von Large Language Models (LLMs) kann die Stimmung in Texten analysiert und in positive, negative oder neutrale Kategorien eingeordnet werden. Ihre Fähigkeit, schnell große Datenmengen verarbeiten zu können, hilft beim Aufdecken von Trends oder Meinungen über Personen oder Ereignisse auf Social Media. Sie können auch Kundenfeedback analysieren und datengesteuerte Einblicke geben, wie Kundenzufriedenheit verbessert werden kann.
- Semantische Suche – Indem LLMs die Absicht einer Eingabe im Kontext verstehen, können sie in der Suchmaschinentechnologie angewendet werden. Sie liefern dabei Inhalte, die der Bedeutung einer Abfrage entsprechen, im Gegensatz zu Inhalten, die mit den Suchbegriffen wortwörtlich übereinstimmen. Eine verbesserte.User Experience kommt E-Commerce Plattformen und anderen Wissensdatenbanken zugute.
Trotz vielseitiger Anwendungsmöglichkeiten versteckt sich ihr wahres Potential in der Art und Weise, wie sie eingesetzt werden – und hier kommt Deepseek ins Spiel.
Wie Deepseek das Potenzial von LLMs ausreizt

Deepseek nutzt LLMs, um Suchergebnise zu verbessern und Ausgaben zu generieren, die relevanter, kontextbezogener und intuitiver sind. Das funktioniert so:
- Präzision durch semantische Suche – Traditionelle Suchmethoden, die auf der Übereinstimmung exakter Schlüsselbegriffe beruhen, liefern häufig Ergebnisse, die den Erwartungen der User nicht entsprechen, wenn bestimmte Schlüsselbegriffe in ihren Suchen fehlen. Die über LLMs in Deepseek integrierte semantische Suche orientiert ihre Suchergebnisse an einer Einschätzung der Absicht und der Bedeutung der Anfrage. LLMs bewerten die Suchanfrage, um Optionen anzubieten, die den tatsächlichen Absichten der Benutzer entsprechen.
- Kontextverständnis – LLMs sind sehr gut darin, den Kontext eines Textes zu verstehen. Über LLMs werden bei Deepseek historische Benutzerinteraktionen, spezifische Merkmale Ihrer Kommunikation mit Deepseek und aktuelle Präferenzen ausgewertet, um Ausgaben zu personalisieren und verfeinern. Ausgaben können sich sogar während der Interaktion ändern, da sich das System an dem User und seinem Verhalten orientiert.
- Dynamic Summarization – Bei dieser Technik kann Deepseek über LLMs bestimmen welche Phrasen eines Dokuments die Konzepte, nach denen der Benutzer sucht, am besten darstellen.Einige Sätze oder Satzteile werden ausgewählt und kombiniert, um die Zusammenfassung zu erstellen, die in den Ergebnissen angezeigt wird.Durch gute Zusammenfassungen sparen sich die Benutzer Zeit und erhalten kondensiert Informationen ohne längere Dokumente oder Artikel lesen zu müssen.
- Domänenspezifische Optimierung – Deepseek kann genutzt werden, um branchenspezifische Modelle mit Fähigkeiten auszustatten, die über allgemeine LLM-Funktionalität hinausgehen. Das ist für Branchen mit eigener Terminologie, wie im Gesundheitswesen, dem Rechtswesen oder dem Bildungssystem wichtig, da Benutzer durch die Weiterleitung branchenspezifischerModelle durch das System von Deepseek präzise branchenspezifische Informationen erhalten, anstatt generischer, allgemeiner oder irrelevanter Antworten.
- Interaktion in natürlicher Sprache – Durch semantische Suche in natürlicher Sprache kann Deepseek Interaktionen auf Plattformen in Expertendialoge verwandeln. Die Fähigkeit detaillierte Suchanfragen zu verstehen und diese mithilfe natürlicher, menschenähnlicher Dialoge zu beantworten verbessert die Interaktion mit den Benutzern und liefert zugängliche Suchergebnisse.
Herausforderungen bei der Nutzung von LLMs
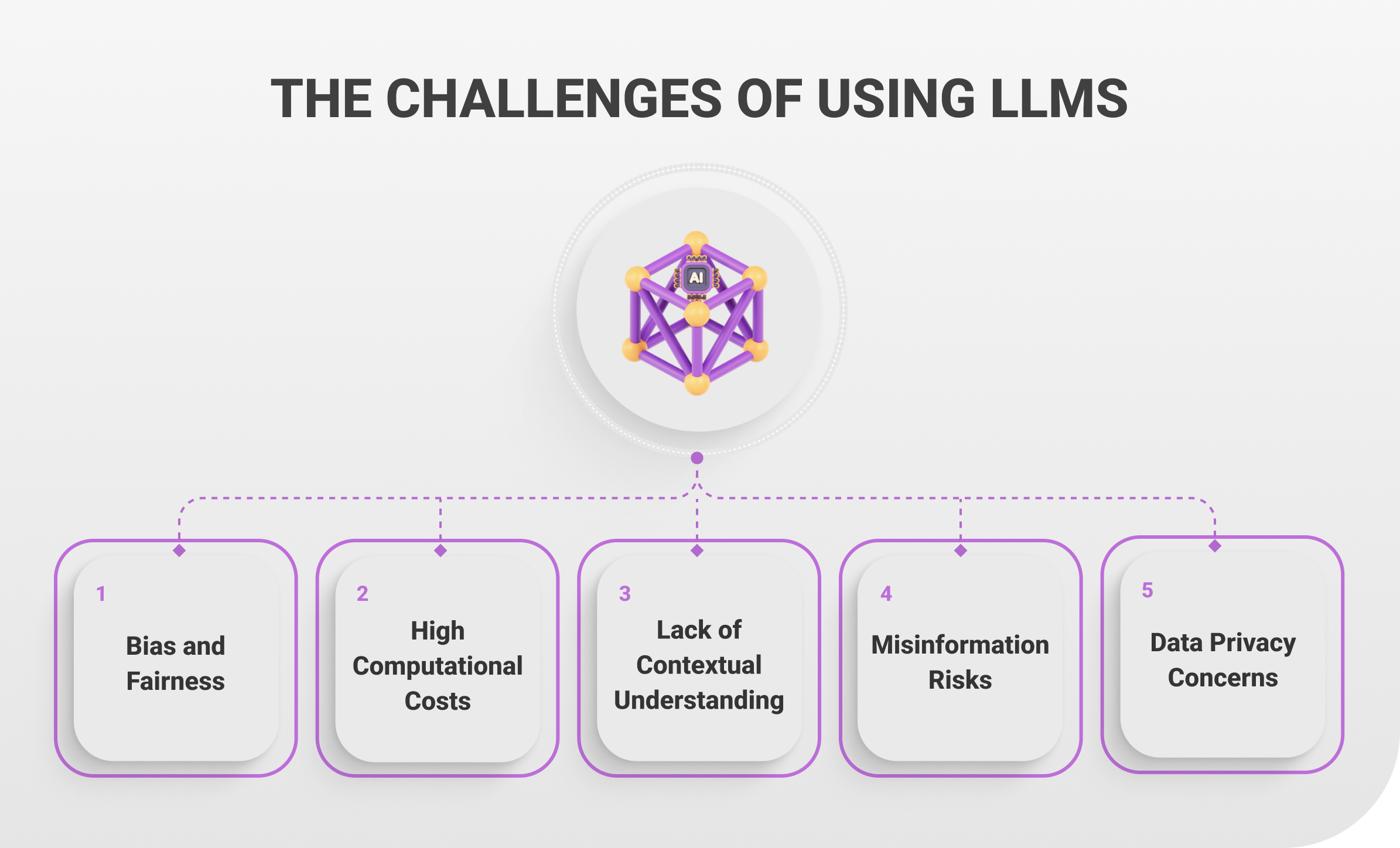
Während Large Language Models (LLMs) branchenübergreifend transformatives Potenzial zeigen, kommt ihre Implementierung oft auch mit erheblichen Herausforderungen. Von technischen Einschränkungen, bis hin zu ethischen Bedenken erfordern diese vorab sorgfältige Überlegungen. Im Folgenden finden Sie fünf Herausforderungen, die bei einem verantwortungsvollen und effektiven Einsatz von LLMs häufig aufkommen.
- Verzerrungen und Fairness – Große Datensätze aus dem Internet, die von Vorurteilen, Stereotypen und nicht-Repräsentativität geprägt sind, bilden in den meisten Fällen die Trainingsgrundlage von LLMs. Die Verwendung dieser Daten erzeugt unbeabsichtigte Ergebnisse, indem sie Verzerrungen in den Ausgaben verursachen, beispielsweise Stereotypen verstärken. LLMs können so bestimmte Berufe oder soziale Rollen mit bestimmten Geschlechtern und Ethnienassoziieren. Erfolgreich dagegen vorzugehen erfordert sorgfältig ausgewählte Trainingsdatenund Tests gegen Verzerrungen, gefolgt von Fine-Tuning. Vor allem in multilingualen und multikulturellen Umgebungen ist es schwer Verzerrungen zu vermeiden und „faire“ LLMs zu entwickeln und eine Herausforderung, die uns noch lange beschäftigen wird.
- Hohe Ausgaben für Computing – Häufig werden für den Betrieb und die Bereitstellung von LLMs viele Graphics Processing Units (GPUs) und Tensor Processing Units (TPUs) benötigt. Umfangreiche Rechenressourcen sind nicht nur teuer, sondern auch eine Belastung für die Umwelt, da sie übermäßig viel Energie verbrauchen. Hohe Anforderungen an Infrastruktur und Kosten sind ein Hindernis für KMUs bei der Entwicklung und Verwendung leistungsstarker Machine Learning Technologien. Es bleibt zu sehen, ob Optimierungstechniken wie Komprimierung und Destillation den Ressourcenbedarf als Herausforderung für den Einsatz von LLMs abschwächen können.
- Mangelndes Verständnis – Große Sprachmodelle generieren einem Kontext angemessene Texte ohne echtes Weltverständnis und menschliche Logik. Das führt dazu, dass manche LLM generierte Texte überzeugend erscheinen, aber Logiktests nicht bestehen, weil sie Falschinformationen enthalten und ein größeres Kontextverständnis fehlt. In manchen Fällen haben LLMs bereits falsche medizinische Empfehlungengegeben oder Rechtsfragen aufgrund falscher Argumentation missverstanden. Die in LLM Ausgaben beobachteten Einschränkungen zeigen, dass sie validiert werden müssen und LLMs eine branchenspezifische Anpassung benötigen, wenn sie in kritischen Anwendungsbereichen eingesetzt werden.
- Fehlinformationen – Wenn LLMs dazu beitragen Fehlinformationen zu generieren oder verbreiten entsteht ein Risiko. Vor allem, wenn mittels LLMs Texte verfasst werden, von denen man ausgehen sollte, dass sie stimmen, beispielsweise beim Verfassen von Nachrichtenartikeln oder akademischen Texten, kann die Verbreitung von falschen Informationen zu einem Problem werden, da das Vertrauen in diese Institutionen untergraben wird. Um diese Probleme zu vermeiden, müssen Organisationen, deren Funktionslogik auf wahren Informationen basiert, Verifizierungssysteme für Inhalte einsetzen und eigene Mitarbeiter schulen, wie KI-generierte Inhaltserstellung funktioniert.
- Datenschutzbedenken – Die Verwendung sensibler oder proprietärer Daten für das Training von LLMs oder in der Interaktion mit ihnen wirft erhebliche Datenschutzbedenken auf. Wenn ein LLM privaten Informationen ausgesetzt ist, besteht das Risiko, dass diese versehentlich in Ausgaben reproduziert werden. Vor allem in Branchen problematisch, in denen personenbezogene Informationen besonders geschützt werden sollten, wie im Rechts- oder Gesundheitswesen. Unternehmen und Organisationen, die LLMs implementieren oder entwickeln, sollten robuste Praktiken für die Verarbeitung von Daten, die Einhaltung geltender Datenschutzbestimmungen und datenschutzfreundliche Techniken wie differentielle Privatsphäre föderales Lernen berücksichtigen
Fazit
Große Sprachmodelle verändern unseren Umgang mit Information und der Suche danach. Plattformen wie Deepseek nutzen das derzeitige Potenzial von LLMs voll aus, indem sie durch semantische Suche, ein kontextuelles Verständnis und domänenspezifische Optimierungsmöglichkeiten beispiellose Suchergebnisse für ihre Nutzer ermöglichen. LLMs entwickeln sich natürlich stets weiter, aber bereits jetzt steht fest, dass Innovationen wie Deepseek zweifellos dazu beitragen, künstliche Intelligenz einem breiteren Publikum zugänglicher zu machen.