Data Annotation Trends im Jahr 2025
Eine steigende Nachfrage an KI- und ML-basierten Anwendungen in fast allen Branchen beflügelt die Nachfrage nach Trainingsdaten. Vor allem wenn Menschenleben auf dem Spiel stehen oder die Algorithmen möglichst robuste Ergebnisse liefern müssen, ist die Qualität der verwendeten Trainingsdaten von entscheidender Bedeutung. Bei der Verarbeitung natürlicher Sprache spielen auch ethische Vorbehalte eine Rolle. Dies alles geschieht im Spannungsfeld zwischen manueller Daten Annotation, bei der Menschen die Trainingsdaten vorbereiten, und KI-gestützte Tools für die Annotierung von Daten, bei der Algorithmen die Trainingsdaten vorbereiten. In diesem Artikel thematisieren wir aktuelle Trends in der Data Annotation Branche, anstehende Herausforderungen und welche zukünftige Innovationen die Beziehung zwischen Mensch und Maschine im Streben nach intelligenter KI neu definieren können.
Übersicht über den Markt für Datenannotation im Jahr 2025
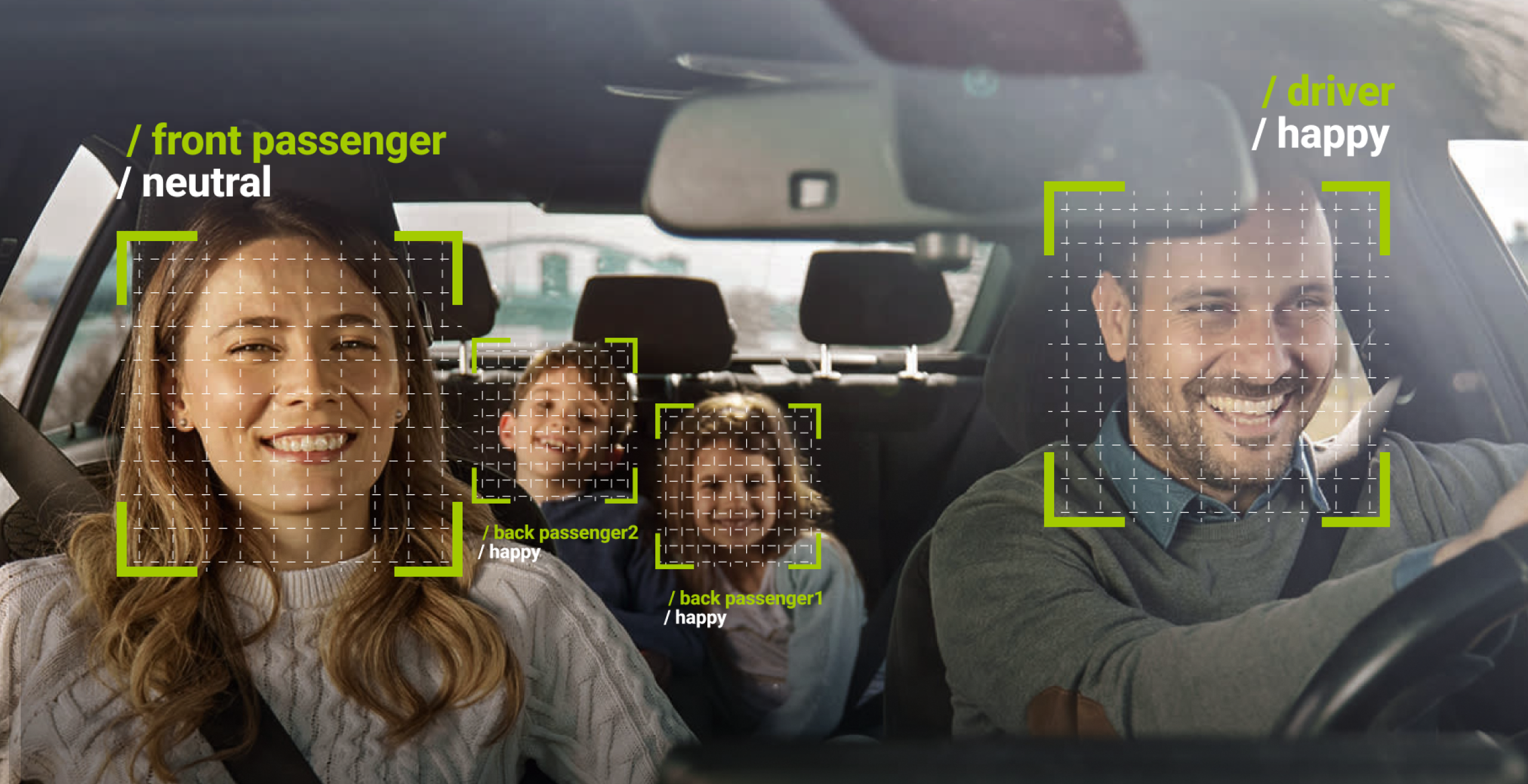
Durch eine weiterhin steigende Nachfrage nach KI-gestützten Anwendungen in Sektoren wie autonomen Fahrzeugen, Gesundheitswesen, Finanzen und im Einzelhandel wird der Markt für annotierte Trainingsdaten auch im Jahr 2025 signifikantes Wachstum erfahren. Der Umsatz wird mittlerweile auf Milliarden von Dollar geschätzt und beheimatet ein kunterbuntes Kaleidoskop verschiedener Plattformen und Anbieter, die auf die Kennzeichnung von Trainingsdaten spezialisiert sind, seien es simple Text- und Bildbeschriftung oder komplexere Aufgaben wie die Erstellung von 3D-Punktwolken. KI-gestützte Tools für die Annotation von Daten gewinnen an Bedeutung, da da sie die manuelle Arbeit reduzieren und gleichzeitig die Effizienz und Genauigkeit verbessern. Human-in-the-Loop-Systeme bleiben jedoch für qualitativ hochwertige Annotationen von entscheidender Bedeutung, insbesondere in sensiblen Bereichen wie der medizinischen Bildgebung oder beim Verständnis natürlicher Sprache. Auch ein verstärkter Fokus auf ethische Überlegungen beim Einsatz von LLMs erhöht den Bedarf an vielschichtigen unverzerrten Trainingsdaten, nach Prüfung des Ursprungs und der Qualität verwendeter Trainingsdaten, sowie der Anpassung der Gewichte der Modelle.
Einflussfaktoren auf die Nachfrage nach annotierten Trainingsdaten
Technologiefortschritt ist der treibende Faktor für die Nachfrage nach Data Annotation Dienstleistungen und Tools. Da mehr und mehr Technologielösungen entwickelt werden, die qualitativ hochwertige Trainingsdaten für KI-Algorithmen benötigen, werden auch mehr annotierte Trainingsdaten benötigt. Die Krux dabei ist, dass schlechte Trainingsdaten zu schlechten Modellleistungen führen, was zu erheblichen Verzögerungen und Problemen bei der Einführung des Produkts führen kann. Deshalb ist vor allem die Nachfrage an qualitativ hochwertigen Trainingsdaten in die Höhe geschnellt. Denn wer will schon, dass sein komfortables Smart Home ihn ausversehen einschließt oder mit einem Chatbot kommunizieren, der ihn rassistisch beschimpft. Kunden erwarten heutzutage, dass sie sich auf die KI-Applikationen, die sie im Alltag nutzen, verlassen können und das geht nur, wenn die verwendeten Trainingsdaten unverzerrt und akkurat sind.
Top 6 Data Annotation Trends im Jahr 2025: Brancheneinblicke und Ausblick

Wir erwarten für 2025 einige Data Annotation Trends, die Sie bei der Erstellung relevanter Trainingsdaten für KI-Applikationen im Auge behalten sollten. So können Sie sich schon einmal vorab informieren und in weiser Voraussicht in Ihre Pläne aufnehmen. Auf diese sechs Trends sollten Sie im kommenden Jahr achten:
- Die Verheißung unstrukturierter Daten – Mit der zunehmenden Nutzung von digitalen Plattformen und vernetzten Geräten ist auch das Volumen unstrukturierter Daten wie Texte, Bilder, Videos und Social-Media Content in den letzten Jahren sprunghaft angestiegen. Diese Explosion unstrukturierter Daten kommt mit Herausforderungen, aber auch Verheißungen und löste einen Wettbewerb um die Entwicklung ausgefeilter Tools und Techniken aus, wie sie sich am besten organisieren und analysieren lassen, um daraus einen geschäftlichen Nutzen zu ziehen.
- Verbreitung von Large Language Models (LLMs) – Diese große generative Sprachmodelle mit Künstlicher Intelligenz können neue Inhalte verstehen, zusammenfassen, generieren und vorhersagen. Bekannte LLMs wie GPT oder BERT sind mittlerweile zu wichtigen Akteuren in der Generierung von Content, dem schreiben von Code oder in der Übersetzung geworden. Es ist davon auszugehen, dass LLMs im Laufe der nächsten Jahre immer ausgefeilter werden.
- Zunehmende Bedeutung visueller Daten – Visuelle Daten spielen für viele KI-Anwendungen eine wichtige Rolle, beispielsweise bei der Entwicklung autonomer Fahrzeuge, bei der Gesichtserkennung oder in der Diagnostik. Das Feld Computer Vision entwickelt sich dynamisch weiter. Algorithmen zur Objekterkennung und Lokalisation verlangen präzise annotierte Trainingsdaten, wie 3D-Modelle und Echtzeit-Videostreams.
- Auch generative KI benötigt große Mengen annotierter Trainingsdaten – wird aber unter anderem dazu verwendet Data Annotation selbst zu automatisieren und beschleunigt eine schnellere und kosteneffektive Erstellung von Trainingsdaten. Im Jahr 2025 geht der Trend von rein manuellen Annotationen hin zu einer Erstannotation durch KI gepaart mit manueller Kontrolle. Vor allem für Großprojekte hat dies den Vorteil, dass viel manuelle Arbeit bei der Kennzeichnung zunächst automatisiert wird und der Fokus auf Qualitätssicherung der KI-gekennzeichneten Daten verlagert wird. Es steigt somit auch die Nachfrage nach KI-gesteuertenTools für Annotationen.
- Automatisierung revolutioniert Workflows bei der Annotation – KI-gestützte Data Annotation Tools werden vermehrt für eine erste Annotation verwendet, sodass sich traditionelle Workflows bei der Annotierung von Trainingsdaten verändern. Wo bei Großprojekten früher alles „von Hand“ erledigt wurde, verbessert Automatisierung der Erstannotation Geschwindigkeit und Effizienz. Stringente Qualitätskontrolle im Anschluss ermöglicht es Unternehmen, die sich mit autonomem Fahren, KI-gestützter Diagnostik im Gesundheitswesen oder der Verarbeitung natürlicher Sprache beschäftigen, trotz Automatisierung eine hohe Qualität der verwendeten Trainingsdaten sicherzustellen.
- Zunehmender Fokus des Gesetzgebers auf KI-Compliance und Datenschutz – Rechtssicherheit und ethische Überlegungen werden bei Entwicklung und Einsatz von künstlicher Intelligenz weiter an Bedeutung gewinnen. Seit der Einführung des Artificial Intelligence Acts (AI Act) im August 2024 sind beispielsweise KI-Anwendungen, die menschliches Verhalten manipulieren, solche, die biometrische Identifizierung in Echtzeit (wie etwa Gesichtserkennung) im öffentlichen Raum nutzen, und solche, die für Social Scoring verwendet werden, in der EU gänzlich verboten. Für Hochrisiko-KI-Systeme gelten zunehmend spezifische Anforderungen, beispielsweise an die Qualität der verwendeten Daten, die Genauigkeit, die Robustheit und die Cybersicherheit. Hochwertige, vielfältige und ethisch einwandfreie Datensätze sind unerlässlich, um Verzerrungen zu reduzieren, die Genauigkeit zu verbessern und die Einhaltung sich entwickelnder regulatorischer Standards sicherzustellen, was Organisationen dazu veranlasst, strengere Praktiken bei Erstellung von Trainingsdaten einzuführen.
Technologietrends, die in den nächsten 10 Jahren wichtig werden
Es gibt natürlich auch Trends, bei denen erwartet wird, dass ihr Einfluss auf den Markt für annotierte Trainingsdaten erst im Laufe des nächsten Jahrzehnts so richtig greift, da die Technologieentwicklung noch in den Kinderschuhen steckt. Zu diesen gehören:
- Quantencomputing – Fortschritte in der Quantentechnologie werden schnellere und komplexere Problemlösungen ermöglichen und Bereiche wie Kryptographie, Arzneimittelforschung und Klimamodellierung oder die Automobilindustrie revolutionieren. So nutzt VW einen Quanten-Annealer von D-Wave, um die Simulation von Verkehrsflüssen und BMW versucht mit Quantencomputern Arbeitsschritte von Fertigungsrobotern zu optimieren.
- Künstliche Allgemeine Intelligenz (AGI) – Hierbei wird versucht versucht, Software mit menschenähnlicher Intelligenz und der Fähigkeit zum Selbststudium zu entwickeln. Ziel ist es, dass sie Aufgaben ausführen kann, für die sie nicht trainiert wurde. Zu den Herausforderungen solcher KI-Systeme gehören Verbindungen zwischen Domains herzustellen, sowie emotionale Intelligenz und Sinneswahrnehmung.
- Edge Computing und 5G/6G – Die Umstellung auf Edge Computing wird zusammen mit der Einführung von 5G- und 6G-Netzwerken eine schnellere, dezentrale Datenverarbeitung unterstützen und das IoT, Echtzeitanalysen und remote Automatisierungslösungen verbessern. Immersive Technologien –
- Immersive Technologien wie Virtual Reality (VR), Augmented Reality (AR) und Extended Reality (XR) erlauben es ihren Usern, in virtuelle Umgebungen einzutauchen. Sie bieten realistische Erlebnisse, werden für Schulungen, Simulationen, und Produktentwicklung genutzt, auch über die Gaming-Branche hinaus, in anderen Sektoren wie im Bildungswesen, im Gesundheitswesen oder bei Remote-Work.
- Biotechnologie und Genome Editing – Fortschritte in CRISPR und der synthetischen Biologie werden Medizin, Landwirtschaft und Umweltschutz verändern und personalisierte Behandlungen und neue Ansätze für Nachhaltigkeit ermöglichen.
Wie Sie 2025 in Sachen Trainingsdaten den Anschluss nicht verlieren
Trends wie Mehrwert aus unstrukturierten Daten, die Verbreitung von Large Language Models (LLMs), generativer KI und KI-gestützter Data Annotation Tools gepaart mit einem zunehmenden Fokus auf KI-Compliance und Datenschutz verlangen, dass Unternehmen kontinuierliches Lernen und Agilität zu einem Teil ihrer DNA machen und sich mit diesen Themen beschäftigen müssen. Investitionen in Expertenwissen, Fachveranstaltungen und Datenqualität werden Ihnen im Jahr 2025 helfen, mit den Entwicklungen auf dem Markt für Trainingsdaten Schritt zu halten. Der Schlüssel zum KI-Erfolg Ihres Unternehmens liegt in einem vorausschauenden Geist und ein Herz für das Lernen. Zögern Sie nicht, bei Fragen rund um das Thema Data Annotation und Trainingsdaten mit Experten Kontakt aufzunehmen!
Häufig gestellte Fragen
Wie groß ist das Marktvolumen für Data Annotation Tools?
Laut Yahoo Finance wird der globale Markt für Data Annotation Tools in den kommenden Jahren voraussichtlich ein erhebliches Wachstum verzeichnen. Bis 2035 werden die Umsätze voraussichtlich etwa 14 Milliarden USD erreichen, was einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von etwa 26 % zwischen 2023 und 2035 entspricht.
Wie wird sich der Markt für Trainingsdaten entwickeln?
Fortschritte in künstlicher Intelligenz und Machine Learning erlauben einen Schritt in Richtung Automatisierung und Rationalisierung bei der Erstellung von Trainingsdaten. Während eine Erstannoation zunehmend von KI-gestützten Tools vorgenommen wird, wird vor allem in Bereichen, in denen akkurat und qualitativ hochwertige Trainingsdaten benötigt werden, die Qualitätskontrolle maschinell annotierter Daten zunehmend in den Fokus rücken. Unter Berücksichtigung von strengeren Anforderungen an KI-Compliance und Datenschutz spielt nicht nur Datenqualität, sondern auch Datenvielfalt eine Rolle, um Verzerrungen in den Ergebnissen zu minimieren.