Datensammlung für maschinelles Lernen
Rohdaten sind ein wesentlicher Bestandteil eines jeden Machine Learning Projekts. Wie aber kommen Sie an Rohdaten? Machen Sie es sich einfach und lassen Sie Mindy Support die erforderlichen Trainingsdaten sammeln.


Typen häufig gesammelter Trainingsdaten
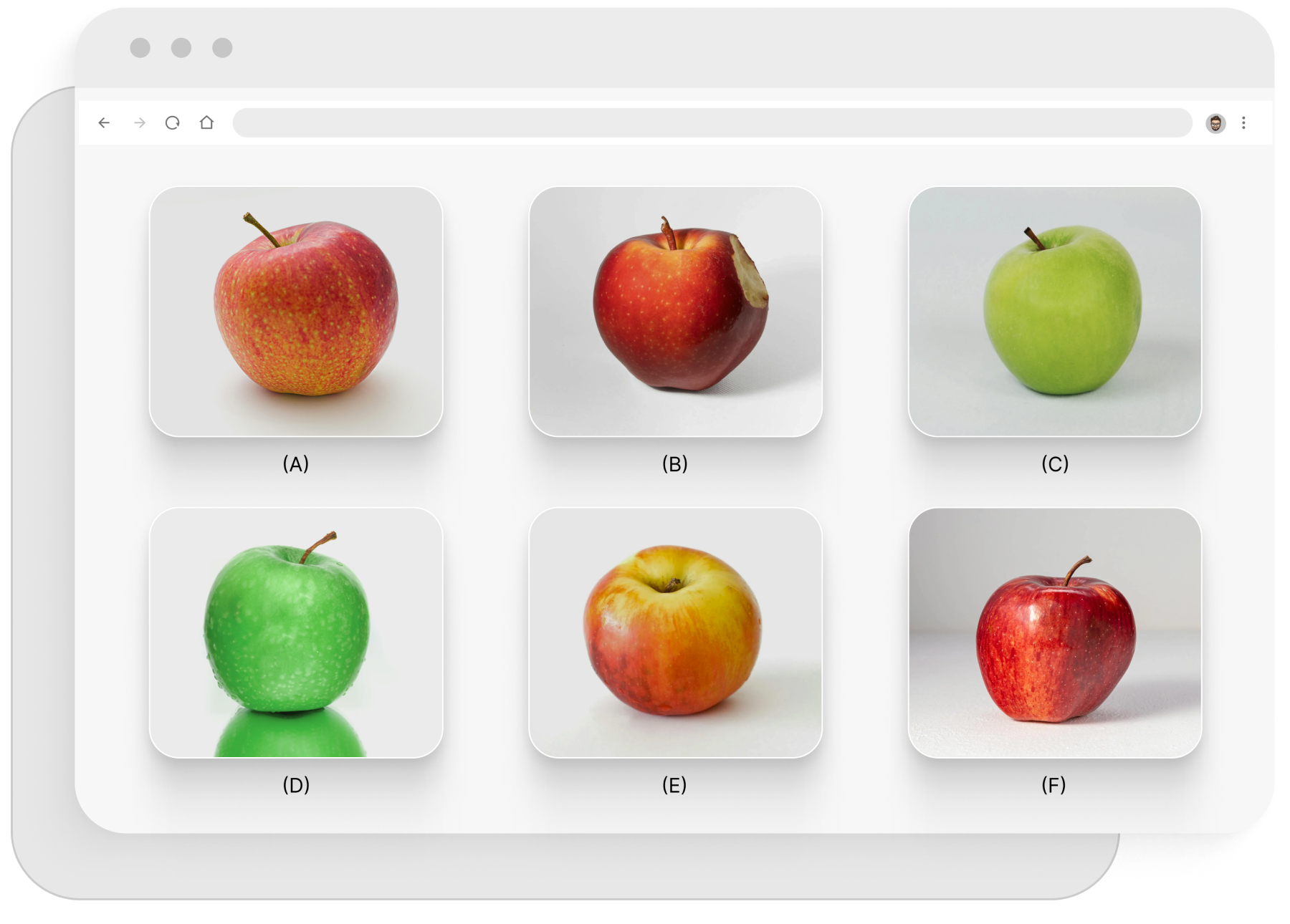
Bilddaten
Einen Datensatz zu finden, der genau die Bilder enthält, die Sie für Ihr ML/KI Projekt benötigen, kann ein zeitaufwändiges Unterfangen sein. Anstatt das Internet selbst zu durchforsten oder für einen vorgefertigten Datensatz zu zahlen, der mehr schlecht als recht für das Modell geeignet ist, können wir einen passgenauen Datensatz für Sie erstellen. Unsere Date Collection Dienstleistungen umfassen ein breites Spektrum verschiedener Bilder für alle Formen von Machine Learning und Deep Learning Anwendungen. Sagen Sie uns einfach, wonach Sie in den Bildern suchen und was das Modell lernen soll, und wir kümmern uns darum.
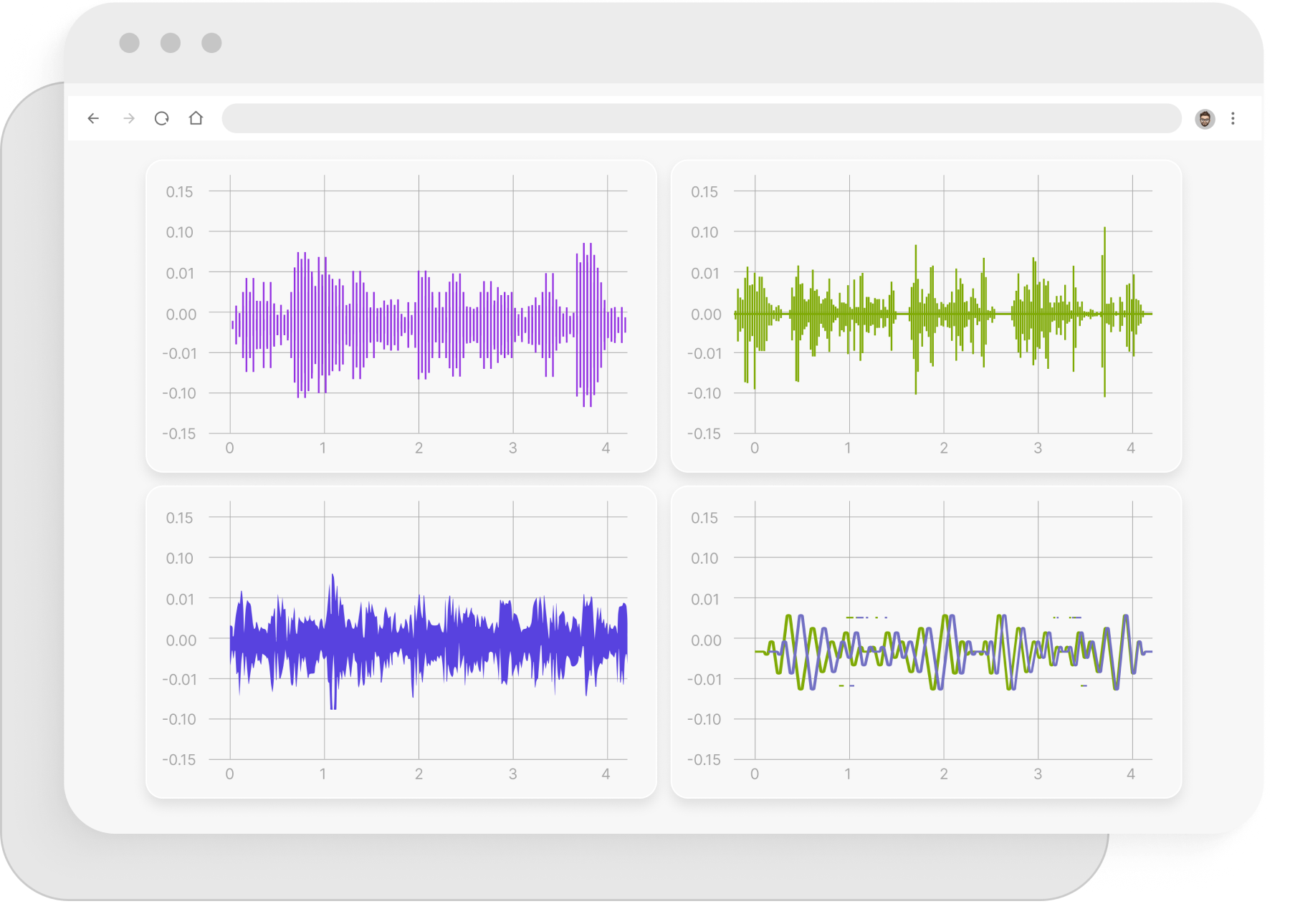
Audiodaten
Wir wissen nur zu gut, wie viele Audiodaten zum Trainieren eines NLP Modells, eines Voice-to-Text Modells oder andere ML-Modelle erforderlich sind, die menschliche Sprache verstehen können. Die Aufnahmen müssen ganz bestimmte Nuancen enthalten, die in echten Dialogen vorkommen, wie Ironie, Sarkasmus und viele andere Details. Wir können Trainingsdaten mit den nötigen Lexika sammeln, sowohl allgemein als auch domänenspezifisch (z. B. Namen, Orte, natürliche Zahlen). Die Audiodaten können zusätzlich als Textkorpora transkribiert und mit morphologischen Informationen und benannten Entitäten annotiert werden.

Textdaten
Heutzutage wird Maschinen beigebracht, Texte zu lesen, zu verstehen, zu analysieren und auf eine für die technologische Interaktion mit Menschen wertvolle Weise zu produzieren. Bevor Machine Learning Modelle natürliche Sprache verstehen können, müssen sie mit ausreichenden Mengen an qualitativ hochwertigen Textdaten trainiert werden. Bei der Sammlung von Textdaten können wir alle Arten von Stimmungen (positiv, negativ, neutral) oder Absichten, die dahinter stehen, wie Befehl, Frage oder Bestätigung, berücksichtigen.

Biometrische Daten
Da es sich bei biometrischen Daten um personenbezogene Daten handelt, die aus einer bestimmten technischen Verarbeitung resultieren und sich auf die physischen, physiologischen oder verhaltensbezogenen Merkmale einer natürlichen Person beziehen, ist die Zustimmung zur Erhebung und Verarbeitung notwendig. Außer Sie haben bereits einen, müssen biometrische Datensätze fast immer neu generiert werden. Wir können Ihnen dabei helfen, erforderliche biometrische Trainingsdaten unter Einhaltung aller Gesetze und Vorschriften zu sammeln, beispielsweise Gesichtsbilder oder personenbezogene Geostandorte.
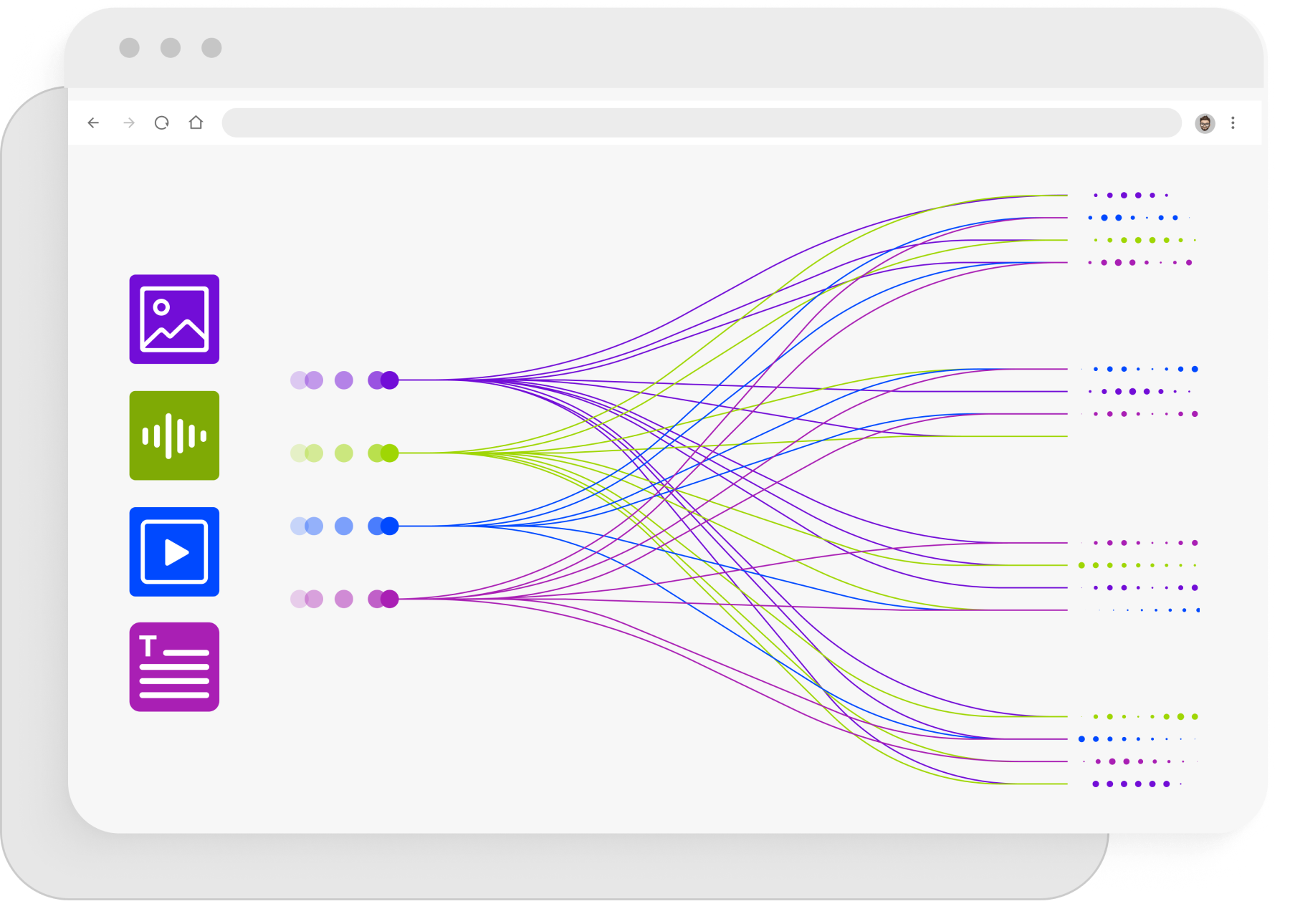
Weitere Datentypen
Wenn Sie einen Trainingsdatensatz benötigen, der nicht aufgeführt ist, können wir auf Anfrage die benötigten Daten für Sie sammeln. Es gibt sehr verschiedene Arten von Machine Learning Unterfangen, manche mit sehr speziellen Anforderungen an benötigte Daten. Mit über 2000 Mitarbeitern und jahrelanger Erfahrung in Datensammlung und Annotation unterstützen wir Sie gerne bei der Zusammenstellung Ihrer Trainingsdaten, im Rahmen dessen, was technisch und rechtlich möglich ist.
Warum arbeiten unsere Kunden mit uns?
Es gibt viele verschiedene Gründe, warum ein externer Datensammlung wie Mindy Support für die Optimierung von (M)LLMs gewählt wird. Dazu gehören:




Globale Präsenz
Unsere globale Reichweite ermöglicht es unseren Kunden, auf mehrsprachige Teams für Data Annotation, LLM Training, KI Beratung und Kundensupport zurückzugreifen. Unser Fachwissen und sprachliche Kompetenzen helfen ihnen, Daten effizient zu verarbeiten, weltweit zu kommunizieren und kulturelle und zeitliche Barrieren zu überwinden.

Fallstudien













Kundenmeinungen

Guilia M
Anyline, Österreich
Dank Mindy Support war der Kunde in der Lage, mehrere maßgeschneiderte mobile OCR-Scanlösungen fristgerecht zu liefern. Sie waren gründlich und reagierten schnell, mit klarer Kommunikation. Ihre beeindruckendste Leistung war die Erstellung von Lösungen innerhalb von Stunden.

Dr. Henning Lategahn
Atlatec GmbH, Deutschland
Wir arbeiten jetzt schon seit einiger Zeit mit Mindy zusammen. Sie unterstützen unsere Teams in Deutschland bei der 3D-Kartografie. Ihre Arbeit ist von unschätzbarem Wert und hilft uns, pünktlich und innerhalb unseres Budgets qualitativ hochwertige Ergebnisse zu erzielen. Sie sind ein vollwertiger Teil unseres Teams. Danke, Mindy.

Nick D.
Viu More, Belgien
Dank Mindy Support hat der Kunde ein effektives Modell entwickelt, das es ihm ermöglicht, die verschiedenen Abfallarten zu unterscheiden. So konnten sie innerhalb von zwei Wochen über 1.000 Bilder mit Anmerkungen versehen. Die Zusammenarbeit mit dem Team ist einfach - es ist aufgeschlossen für Feedback, sympathisch und kommunikativ.

Emma Schuster
Sweatcoin, Vereinigtes Königreich
Das Mindy Support Team verstand seine Rolle sofort und konnte alle Bedürfnisse ihres Kunden erfüllen. Sie bemühen sich proaktiv um Feedback und sind äußerst reaktionsschnell. Mit guten Projektmanagement-Kompetenzen konnten sie einen tollen Service und effektive Arbeitsabläufe sicherstellen. Immer ansprechbar ist das Mindy Team auch stets zur Stelle, wenn es gebraucht wird.

Antoine S.
Kili Technology
Der Kunde war mit der Leistung von Mindy Support sehr zufrieden. Die Qualität der Kommentare und das Arbeitstempo waren beeindruckend. Sie sind reaktionsschnell und organisiert und ermöglichen einen nahtlosen Arbeitsablauf, der eine langfristige Partnerschaft fördert.

Tyler M.
Superb AI
Das Beeindruckendste an Mindy Support ist ihre Fähigkeit, Schnelligkeit mit Präzision zu verbinden und dabei die Kosteneffizienz zu wahren. Ihre Fähigkeit, Projektanforderungen schnell zu erfassen und qualitativ hochwertige Anmerkungen innerhalb strenger Fristen zu liefern, ist lobenswert und hat maßgeblich zum Erfolg unserer Projekte beigetragen.

René Bolier
OnRecruit, Niederlande
Für uns bot Mindy Support ein gutes Return on Investment. Viele Treffen mit potenziellen Neukunden wurden allein durch ihre Arbeit zum Erfolg. Auf persönlicher Ebene war die Zusammenarbeit mit Tetiana und Evgenia sehr angenehm. Sollten wir in diesem Bereich wieder Fachwissen benötigen, wäre Mindy Support auf jeden Fall unser erster Ansprechpartner.